Imagine a world where organizations effortlessly unlock their data ecosystem’s full potential as data lineage, cataloging, and quality seamlessly flow across platforms. As we rely more and more on data, the technology for uncovering valuable insights has grown increasingly nuanced and complex. While we’ve made significant progress in collecting, storing, aggregating, and visualizing data to meet the needs of modern data teams, one crucial factor defines the success of enterprise-level data platforms — Data observability.
Data observability is often conflated with data monitoring, and it’s easy to see why. The two concepts are interconnected, blurring the lines between them. However, data monitoring is the first step towards achieving true observability; it acts as a subset of observability.
Some of the industry-level challenges are:
- The proliferation of data sources with varying tools and technologies involved in a typical data pipeline diminishes the visibility of the health of IT applications.
- Data is consumed in various forms, making it harder for data owners to understand the data lineage.
- The complexity of debugging pipeline failures poses major hurdles with a multi-cloud data services infrastructure.
- Nonlinearity between creation, curation, and usage of data makes data lineage tough to track.
What is Data Observability?
To grasp the concept of data observability, the first step is to understand what it entails. Data observability focuses on examining the health of enterprise data environments by focusing on:
- Design Lineage: Providing contextual data observations such as the job’s name, code location, version from Git, environment (Dev/QA/Prod), and data source metadata like location and schema.
- Operational Lineage: Generating synchronous data observations by computing metrics like size, null values, min/max, cardinality, and more custom measures like skew, correlation, and data quality validation. It also includes usage attributes such as infrastructure and resource information.
- Tracing and Continuous Validation: Generating data observations with continuously validated data points and sources for efficient tracing. It involves business thresholds, the absence of skewed categories, input and output data tracking, lineage, and event tracing.
Implementing Data Observability in Your Lakehouse Environment
Benefits of Implementation
- Capturing critical metadata: Observability solutions capture essential design, operational, and runtime metadata, including data quality assertions.
- Seamless integration: Technical metadata, such as pipeline jobs, runs, datasets, and quality assertions, can seamlessly integrate into your enterprise data governance tool.
- End-to-end data lineage: Gain insights into the versions of pipelines, datasets, and more by establishing comprehensive data lineage across various cloud services.
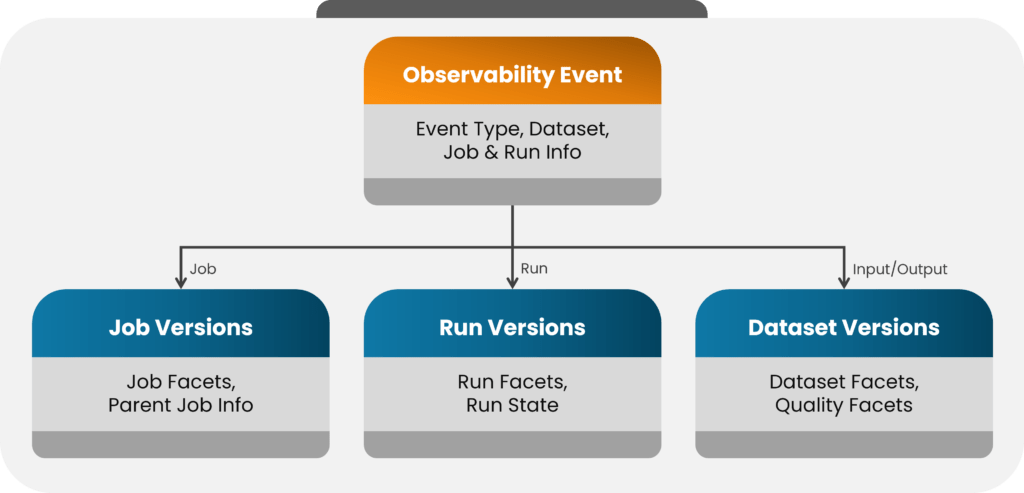
Essential Elements of Data Observability Events
- Job details: Name, owner, version, description, input dependencies, and output artifacts.
- Run information: Immutable version of the job, event type, code version, input dataset, and output dataset.
- Dataset information: Name, owner, schema, version, description, data source, and current version.
- Dataset versions: Immutable versions of datasets.
- Quality facets: Data quality rules, results, and other relevant quality facets.
Implementation Process
A robust and holistic approach to data observability requires a centralized interface in data. So, end-to-end data observability consists of implementing the below four layers in any of the Lakehouse environments.
- Observability Agent: A listener setup that depends on the sources/data platform.
- Data Reconciliation API: An endpoint for transforming the event to fit into the data model.
- Metadata Repository: A data model created in a relational database.
- Data Traceability Layer: A web-based interface or existing data governance tool.

By implementing these four layers and incorporating the essential elements of data observability, organizations can achieve improved visibility, traceability, and governance over their data in a Lakehouse environment.
The core data model for data observability prioritizes immutability and timely processing of datasets, which are treated as first-class values generated by job runs. Each job run is associated with a versioned code and produces one or more immutable versioned outputs. Changes to datasets are captured at various stages during job execution.
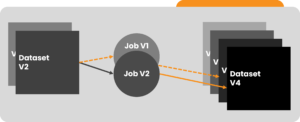
Technical Architecture: Observability in a Modern Platform
The depicted technical architecture exemplifies the implementation of a data observability layer for a modern medallion-based data platform. It helps enable a data observability layer for an enterprise-level data platform that collects and correlates metrics.
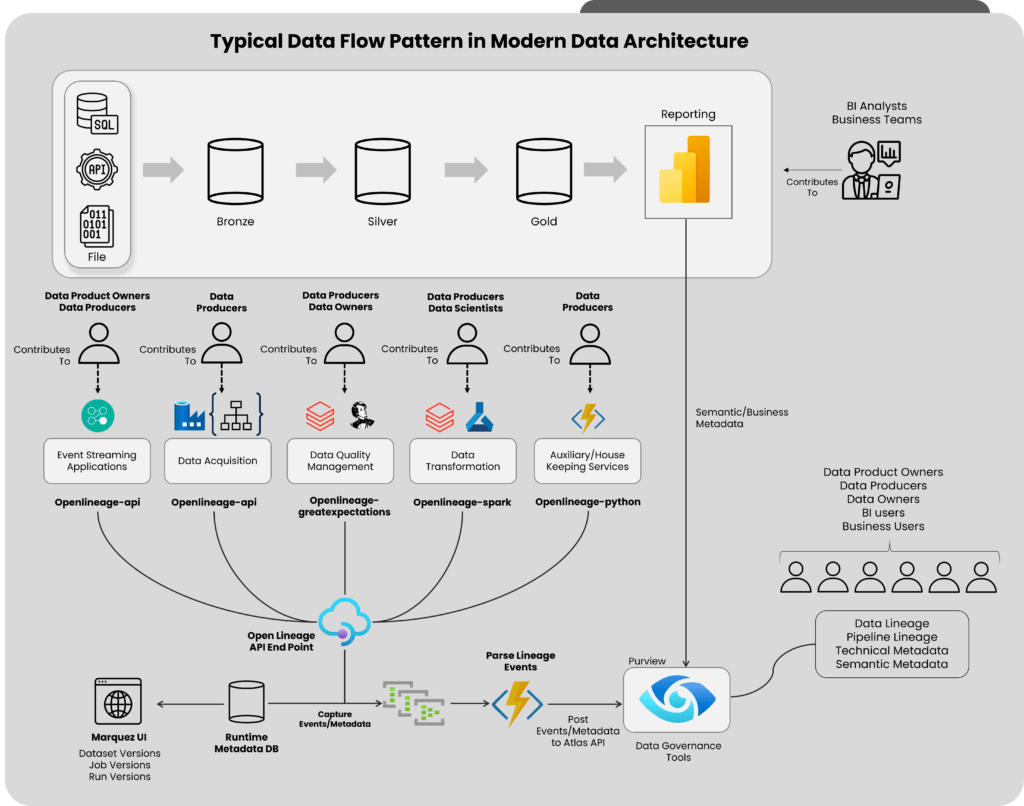
In data observability, this robust architecture effectively captures and analyzes critical metadata. Let’s dive into the technical components that make this architecture shine and understand their roles in the observability layer.
OpenLineage Agent
This observability agent bridges data sources, processing frameworks, and the observability layer. Its mission is to communicate seamlessly, ingesting custom facets to enhance event understanding. The OpenLineage agent’s compatibility with a wide range of data sources, processing frameworks, and orchestration tools makes it remarkable. In addition, it offers the flexibility needed to accommodate the diverse technological landscape of modern data environments.
OpenLineage API Server
As the conduit for custom events, the OpenLineage API Server allows ingesting these events into the metadata repository.
Metadata Repository
The metadata repository is at the heart of the observability layer. This data model, carefully crafted within a relational data store, captures essential information such as jobs, datasets, and runs.
Databricks
Azure Databricks offers powerful data processing engine with various types of clusters. Setting up OpenLineage agent in Databricks cluster enables to capture the dataset lineage tracking events based on the data processing jobs triggered in the workspace.
Azure Data Factory
With its powerful data pipeline orchestration capabilities, Azure Data Factory (ADF) takes center stage. ADF enables the smooth flow of data pipeline orchestration events, seamlessly sending them to the OpenLineage API. ADF seamlessly integrates with the observability layer, further enhancing data lineage tracking.
Great Expectations
Quality is of paramount importance in any data-driven ecosystem. Great Expectations ensures that quality facets are seamlessly integrated into each dataset version. Also, by adding custom facets through the OpenLineage API, Great Expectations fortifies the observability layer with powerful data quality monitoring and validation capabilities.
EventHub
As the intricate events generated by the OpenLineage component must be seamlessly integrated into the Apache Atlas API from Purview, EventHub takes center stage. As an intermediate queue, EventHub diligently parses and prepares these events for further processing, ensuring smooth and efficient communication between the observability layer and Purview.
Function API
To facilitate this parsing and preparation process, Azure Functions come into play. Purpose-built functions are created to handle the OpenLineage events and transform them into Atlas-supported events. These functions ensure compatibility and coherence between the observability layer and Purview, enabling seamless data flow.
Purview
Finally, we have Purview, the ultimate destination for all lineage and catalog events. Purview’s user interface becomes the go-to hub for tracking and monitoring the rich lineage and catalog events captured by the observability layer. With Purview, users can gain comprehensive insights, make informed decisions, and unlock the full potential of their data ecosystem.
Making Observability Effective on the ADB Platform
At Tiger Analytics, we’ve worked with a varied roster of clients, across sectors to help them achieve better data observability. So, we crafted an efficient solution that bridges the gap between Spark operations in Azure Databricks and Azure Purview. It transfers crucial observability events, enabling holistic data management. This helps organizations thrive with transparent, informed decisions and comprehensive data utilization.
The relationship is simple. Azure Purview and Azure Databricks complement each other. Azure Databricks offers powerful data processing and collaboration, while Azure Purview helps manage and govern data assets. Integrating them allows you to leverage Purview’s data cataloging capabilities to discover, understand, and access data assets within your Databricks workspace.
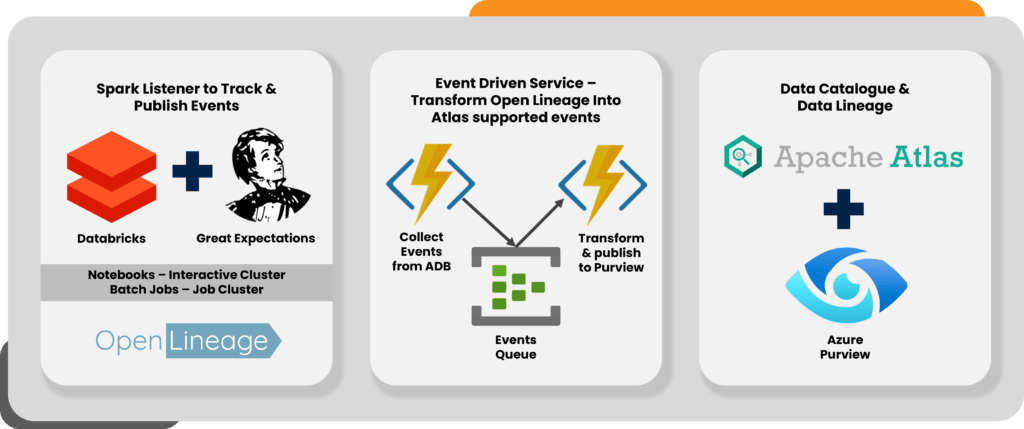
How did we implement the solution? Let’s dive in and find out.
Step 1: Setting up the Environment: We began by configuring the Azure Databricks environment, ensuring the right runtime version was in place. To capture observability events, we attached the OpenLineage jar to the cluster, laying a solid foundation for the journey ahead.
Step 2: Cluster Configuration: Smooth communication between Azure Databricks and Azure Purview was crucial. To achieve this, we configured the Spark settings at the cluster level, creating a bridge between the two platforms. By specifying the OpenLineage host, namespace, custom app name, version, and extra listeners, we solidified this connection.
Sample code snippet:
spark.openlineage.host http://<<<host-ip>>>:5000
spark.openlineage.namespace <<<namespace>>>
spark.app.name <<<custom-app-name>>>
spark.openlineage.version v1
spark.extraListeners io.openlineage.spark.agent.OpenLineageSparkListener
Step 3: Spark at Work: With Spark’s power, the OpenLineage listeners came into action, capturing the Spark logical plan. This provided us with a comprehensive view of data operations within the cluster.
Step 4: Enter the Service Account: This account, created using a service principle, took center stage in authenticating the Azure Functions app and Azure Purview. Armed with owner/ contributor access, this service account became the key to a seamless connection.
Step 5: Azure Purview Unleashed: To unlock the full potential of Azure Purview, we created an Azure Purview service. Within Purview Studio, we assigned the roles of data curator, data source administrator, and collection admin to the service account. This granted the necessary permissions for a thrilling data management adventure.
Step 6: Seamless Deployment: Leveraging the deployment JSON provided in the OpenLineage GitHub repository, we embarked on a smooth AZ deployment. This process created essential services such as storage accounts, blob services, server farms, and websites, laying the foundation for a robust data lineage and cataloging experience –
Microsoft.Storage/storageAccounts
Microsoft.Storage/storageAccounts/blobServices/containers
Microsoft.Web/serverfarms
Microsoft.Web/sites
olToPurviewMappings
Microsoft.EventHub/namespaces
Microsoft.EventHub/namespaces/eventhubs
Microsoft.KeyVault/vaults
Microsoft.KeyVault/vaults/secrets
Step 7: Access Granted: An authentication token was added, granting seamless access to the Purview API. This opened the door to a treasure trove of data insights, empowering us to delve deeper into the observability journey.
Step 8: Spark and Azure Functions United: In the final step, we seamlessly integrated Azure Databricks with Azure Functions. By adding the Azure Function App URL and key to the Spark properties, a strong connection was established. This enabled the capture of observability events during Spark operations, effortlessly transferring them to Azure Purview, resulting in a highly effective data lineage.
Sample code snippet:
spark.openlineage.host https://<functions-app-name>.azurewebsites.net
spark.openlineage.url.param.code <function-app-host-key>
By following the steps outlined above, our team successfully provided a comprehensive and highly effective data lineage and observability solution. By linking parent and child job IDs between Azure Data Factory (ADF) and Databricks, this breakthrough solution enabled correlation among cross-platform data pipeline executions. As a result, the client could leverage accurate insights that flowed effortlessly. This empowered them to make informed decisions, ensure data quality, and unleash the true power of data.

Extending OpenLineage Capabilities Across Data Components
Enterprises require data observability across multiple platforms. OpenLineage, a powerful data observability solution, offers out-of-the-box integration with various data sources and processing frameworks. However, what if you want to extend its capabilities to cover other data platform components? Let’s explore two simple methodologies to seamlessly integrate OpenLineage with additional data platforms, enabling comprehensive observability across your entire data ecosystem:
1. Custom event through OpenLineage API: Maintain a custom function to generate OpenLineage-supported JSON with observability events and trigger the function with required parameters wherever the event needs to be logged.
2. Leveraging API provided by target governance portal: Another option is to leverage the APIs provided by target governance portals. These portals often offer APIs for Data observability event consumption. By utilizing these APIs, you can extend OpenLineage’s solution to integrate with other data platforms. For example, Azure Purview has an API enabled with Apache Atlas for event ingestion. You can use Python packages such as PyApacheAtlas to create observability events in the format supported by the target API.
Data observability continues to be an important marker in evaluating the health of enterprise data environments. It provides organizations with a consolidated source of technical metadata, including data lineage, execution information, data quality attributes, dataset and schema changes generated by diverse data pipelines, and operational runtime metadata. This helps operational teams conduct precise RCA.
As various data consumption tools are in demand, along with the increasing use of multi-cloud data platforms, the data observability layer should be platform-agnostic and effortlessly adapt to available data sources and computing frameworks.
Sources:
https://learn.microsoft.com/en-us/azure/purview/register-scan-azure-databricks
https://learn.microsoft.com/en-us/azure/databricks/introduction/
https://www.linkedin.com/pulse/what-microsoft-azure-purview-peter-krolczyk/





