How can leaders make better, more trustworthy decisions regarding technology? According to the World Economic Forum, that’s where Digital Trust can help steer both companies and customers toward a win-win outcome.
“Privacy serves as a requirement to respect individuals’ rights regarding their personal information and a check on organizational momentum towards processing personal data autonomously and without restriction. A focus on this goal ensures that organizations can unlock the benefits and value of data while protecting individuals from the harms of privacy loss. It effectuates inclusive, ethical, and responsible data use – or digital dignity – by ensuring that personal data is collected and processed for a legitimate purpose(s) (e.g., consent, contractual necessity, public interest, etc.)”
The issue with today’s technology is how to gather insights that can help make better decisions that follow privacy regulations. With the privacy regulations enforcing principles like ‘Right to be Forgotten,’ ‘Privacy by Design,’ ‘Data Portability,’ etc., a checkbox approach to Data Privacy is not sustainable. A paradigm shift in privacy mindset is necessary to mitigate the risks arising due to the use of disruptive technologies.
Organizations need to keep in mind the following aspects of the Data privacy approach while building privacy considerations into their software or services:
Data Classification – Confidential, sensitive, sensitive but need re-use, sensitive but not re-use, etc., based on data classification methodology
Anonymization – This is a process of data de-identification that produces data where individual records cannot be linked back to an original as they do not include the required translation variables to do so. This is an irreversible process.
Re-Identification – The process of re-identifying the de-identified data using the referential values by using the same methods as of De-Identification.
Format Preserving Encryption – The process of transforming data in such a way that the output is in the same format as the input using cipher keys and algorithms.
De-Identification – The process of removing or obscuring any personally identifiable information from individual records in a way that minimizes the risk of unintended disclosure of the identity of individuals and information about them. The data can be reversible. However, it may also include the required translation variables to link back the data to the original data using different mechanisms based on the below table.
Encryption – The process of transforming data using cipher keys and algorithms to make it unreadable cipher text to anyone except those possessing a key. Restoring the data needs both algorithm and cipher keys.
The Data Privacy Approach – From Theory to Implementation
At Tiger Analytics, we built a globally scaled Data and Analytics platform for a US-based Life sciences org, with data discovery and classification as a core component – with the help of AWS Macie, which classifies data based on content, Regex, file extension, and PII classifier.
- Masking sensitive data by partially or fully replacing characters with symbols, such as an asterisk (*) or hash (#).
- Replacing each instance of sensitive data with a token, or surrogate, string.
- Encrypting and replacing sensitive data using a randomly generated or pre-determined key.
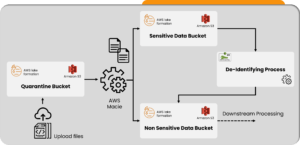
By leveraging best-in-the-class encryption and masking solutions, we were able to protect sensitive data elements in hyperscalers/cloud natives of our clients and their customers.
Deep diving into De-Identification
Different De-identification methods are described in the table below with an example:

Understanding the Encryption Approach
Data Privacy Encryption is achieved through leveraging a new encryption technique, FPE (Format Preserving Encryption), which preserves the format of the sensitive data fields while providing an advanced encryption standard level of encryption strength.

In a typical scenario, data from the source systems will land on the landing zone over a secure channel, and data encryption, masking, and other security measures will be applied, depending on data structure and other library integrations.
Data encryption involves the installation and configuration of 3rd party encryption and key management solution on the Cloud (AWS/GCP) platform. Encryption keys are stored and managed within the Key Management Server, and only authorized users/resources are granted access to the same.
In the case of structured data, sensitive data (specific PII / PHI attributes) will be encrypted without altering the original format. This will be done using the 3rd party Format Preserving Encryption (FPE) solution to preserve business value and referential integrity across distributed data sets when the data moves from un-trusted to a trusted zone at the landing layer. In the case of unstructured data, either the entire file or specific PII/PHI data will be encrypted during the transition from un-trusted to trusted zone on a case-by-case basis, based on the requirements.
Users requiring access to sensitive data (PII/PHI) will be made part of the relevant IAM roles, user credentials will be validated against the IAM, and the data will be transparently decrypted using the keys. Validated users will be able to access the sensitive data in the clear, whereas users who do not have the necessary privileges will see the data only in an encrypted format.
Data Encryption on AWS and GCP – How they Differ
Whenever data is written to the storage platform, AWS will apply encryption on it, and conversely, when the data is read from the storage, decryption will happen transparently. In addition to encryption of specific PII/PHI data, AWS native transparent encryption & KMS features shall be leveraged to protect the data in the AWS cloud. These features will provide protection to data stored in any potential storage mechanism, such as S3, Kinesis, Redshift, Dynamo DB, etc.
Google adds differential privacy to Google SQL for BigQuery, building on the open-source differential privacy library that is used by Ads Data Hub and the COVID-19 Community Mobility Reports. Differential privacy is an anonymization technique that limits the personal information that is revealed by an output. Differential privacy is commonly used to allow inferences and to share data while preventing someone from learning information about an entity in that dataset.
With BigQuery differential privacy, we can:
- Anonymize results with individual-record privacy.
- Anonymize results without copying or moving your data, including data from AWS and Azure with BigQuery Omni.
- Anonymize results that are sent to Dataform pipelines so that they can be consumed by other applications.
- Anonymize results that are sent to Apache Spark stored procedures.
Let’s take the example of a person opening a bank account on a web portal. They have to fill in their age, telephone number, and country. Let’s look at how their Data Privacy can be protected while gathering the necessary information.
Points to note:
- The age field is sensitive, and its actual value is usually not required for any analysis/processing by downstream systems.
- The telephone number is sensitive in nature, and its value in the same format (not actual) is required by the data analytics platform for further analysis. The actual value of the telephone number is required only on-premise.
- Country value is not classified as sensitive; however, its value is encrypted while sending the data to the cloud.
- Data is transmitted between two systems on-premise, on cloud and on-premise to cloud or cloud to on-premise over HTTPS.
- BU-specific encryption keys are used for encryption while moving to the cloud. Data gets decrypted on the premise using the BU-specific keys.
- On-Cloud data at rest is implemented using the cloud provider’s key by applying the techniques of transparent DB encryption, Volume encryption, or Disk encryption.
- Required governance controls at process (for example, approvals for access), people (for example, trainings, background checks, etc.), and technical tools (for example, authentication and access control) are created on-premise and as well as cloud.
- It is assumed that age is not required for further processing, and telephone number is required for analysis and processing by the Data Analytics platform.
- Telephone number is sensitive in nature, and its value in the same format (not actual) is required by the Data Analytics platform for further analysis. The actual value of the Telephone number is required only on-premise.
- The ‘Country’ value is not classified as sensitive; however, its value is encrypted while sending the data to the cloud.
- Based on the data classification, the age value gets anonymized. This is a one-way process.
- The Telephone number gets De-identified using the de-identification method or algorithm by preserving the referential value.
- The country value is encrypted using format preserving encryption algorithm and BU-specific encryption key.
- Then age (anonymized), telephone number (de-identified), and country (encrypted) will be sent to Data Analytics Platform on cloud over HTTPS.
- The data then gets stored in the cloud platform in an encrypted format using the cloud provider’s server-side encryption keys.
- The data at rest on cloud is always in an encrypted format by using the cloud provider’s features like Transparent DB encryption, Volume Encryption, and/or Disk encryption techniques.
- If the data needs to processing by the Analytics platform – the data first gets decrypted using the Cloud Provider’s specific key – complete processing
- Once processing is completed, the data again gets encrypted and stored on Cloud.
- The decryption and re-identification techniques are applied on-premise to retrieve the original values to be consumed by other applications such as call center, ESB, etc.
Final thoughts
“Digital trust is individuals’ expectation that digital technologies and services – and the organizations providing them – will protect all stakeholders’ interests and uphold societal expectations and values.” And ensuring the right privacy considerations, transparent communication, and intent will go a long way in building a mutually trustworthy exchange between organizations and individuals.
Sources:
The Digital Trust report: https://initiatives.weforum.org/digital-trust/about
https://fpf.org/blog/a-visual-guide-to-practical-data-de-identification/





