Every time you watch your favorite web series on Netflix or shop for an item of your choice on Amazon, you get a recommendation for something similar. That’s pretty common across retail, e-Commerce, and streaming platforms – it’s not so common when you’re looking to buy properties online.
The world of real-estate typically focuses on promoting listings based on their commission, as opposed to a buyer’s preference. What if prospective homebuyers could get recommendations for houses they might like, based on their tastes and preferences, just like the recommendations we get across our e-Commerce platforms or media sites?
One of our clients at Tiger Analytics is a leading provider of online real-estate classifieds, and they had this same question. They wanted to unlock the potential of user Clickstream data for personalized recommendations; and through that, improve business outcomes such as Click Through Rates (CTR) and Conversions. Before the use of AI recommender systems, they had a heuristic rule engine in place, which was focused on promotional packages bought by sellers (brokers, builders, etc.).
Clickstream data is quintessential big data – it is high volume meaning a large amount of information across users and touchpoints, and high velocity meaning that new data is generated with every user action. With this kind of data, there are two major challenges.
Challenge #1: Efficient processing and Storage of Data so that it could be easily queried
To overcome the first challenge, we implemented a lakehouse architecture using Databricks Delta Lake. Our client’s setup had a set of components that were deployed on the AWS cloud:
- Apache Kafka, which logs user actions in real time.
- Delta Lake, which processes and stores events from live and completed sessions.
- A structured data store such as MySQL, which stores static information such as user demographics and browsing history.
- Databricks Delta Tables, which is used to access the data by creating the required end-to-end data pipelines on it.
Challenge #2: Separating signal from noise i.e., identifying and using patterns in it to provide more relevant recommendations
To tackle this, we developed a bespoke recommendation framework that used custom-created attributes for users and properties. These attributes were identified by analyzing historical data on search filters applied, user-property touchpoints, and eventual lead submissions. An implicit rating for properties was derived based on the kind of touchpoint – page visit, interaction with photos/videos, etc. – and its correlation with lead submission. To generate the recommendations, we used both the classic approaches, collaborative and content-based filtering.
In collaborative filtering, the goal is to find users who have similar implicit rating behavior across properties. The premise is that if User A and User B have rated several properties similarly, User A would want to see properties highly rated by User B that they haven’t seen before. In content filtering, the focus is on the user’s past behavior. By looking at the profile of properties that a user previously interacted with, new properties with a similar profile are recommended. Here, the features of the property matter and not other users. However, both approaches have what is known as a ‘cold start’ problem. This means that in the absence of browsing history, they cannot provide useful recommendations. To address this, we defined a heuristic set of rules based on overall property popularity to cater to users in the initial stages of their browsing journey.
The final production setup had two parts:
- An offline model which was a combination of both content and collaborative filtering scored every hour and automatically retrained every 6 hours.
- An online model based on content filtering using recent activity.
- Heuristic rules framework, which is based on intelligent cohort-level popularity for generating recommendations to cold start users
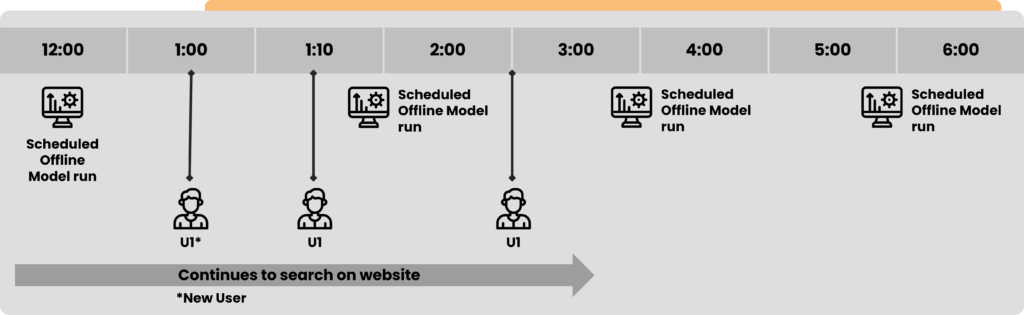
A completely new user would be served recommendations based on cold start rules. As the visitor browses more, the two-part recommendation model comes into play. Initially, just the online model is used to generate recommendations. The framework identifies users and retrieves their user profile. Next it identifies an eligible set of properties post-search filter applied by the user. Passing these properties and user profile to an online content-filtering framework would help in arriving at top recommendations.
The offline recommendations are run in a batch every hour, and recommended properties are stored using Amazon RDS (an AWS service to scale relational databases). Offline recommendations are served as is initially. Upon further continuing their live search session, offline recommendations are refreshed and re-ranked considering some of the more recent interactions by using the online model.
Impact created:
- Incoming visitors on the app/website get relevant house recommendations depending on their association journey with the client.
- These recommendations could be slightly broader for new visitors (cold start) because of their limited preference and search history with the client.
- However, the previous users get fairly appropriate recommendations of their interest.
- Quicker progression along their search journey, leading to better and faster conversions and significantly better visitor experience
- Increased interactions across a wider range of properties leading to higher exposure coverage and, thus, benefitting sellers.
The model is deployed on an Amazon EKS cluster (an AWS-managed service for Kubernetes), allowing it to scale with high volumes of recommendation requests. For a particular request, the relevant user and property features are fetched, and then the recommendations from the hybrid model are generated and provided to the user. This system is dynamic and keeps learning, with recommendations getting enriched over time. The hybrid model also prevents over-personalization of recommendations. Using this solution, the company increased coverage of properties by 22% on the website.
A system like this puts a user’s (in this case, the homebuyer’s) preferences at the forefront. It learns continuously to adapt to the user’s changing requirements. It provides recommendations in real-time, powered by a data engineering architecture geared for low latency. This process makes it easier for homebuyers to find their dream home in minutes, and according to their own preferences, without having to spend hours combing through less-than-perfect listings.





