Let’s say you’re looking to invest for retirement. You want the investment to give you a guaranteed stream of payments post-retirement. You also want it to be linked to the performance of the market. Insurance companies sell such an instrument called a Variable Annuity. To protect investors like us, governments regulate these annuities. They also mandate insurance companies and finance professionals to review whether a particular annuity product suits the investor.
For an insurance company, however, complying with this mandate can involve a lot of intricacies. How to make sure this process is not resource-intensive? How to take into account all the data available? These were problems a large insurer engaged with Tiger Analytics to solve.
They had a rules engine with manually created rules, but it led to lower approval rates. The question was, can this process be augmented with Artificial Intelligence from data?
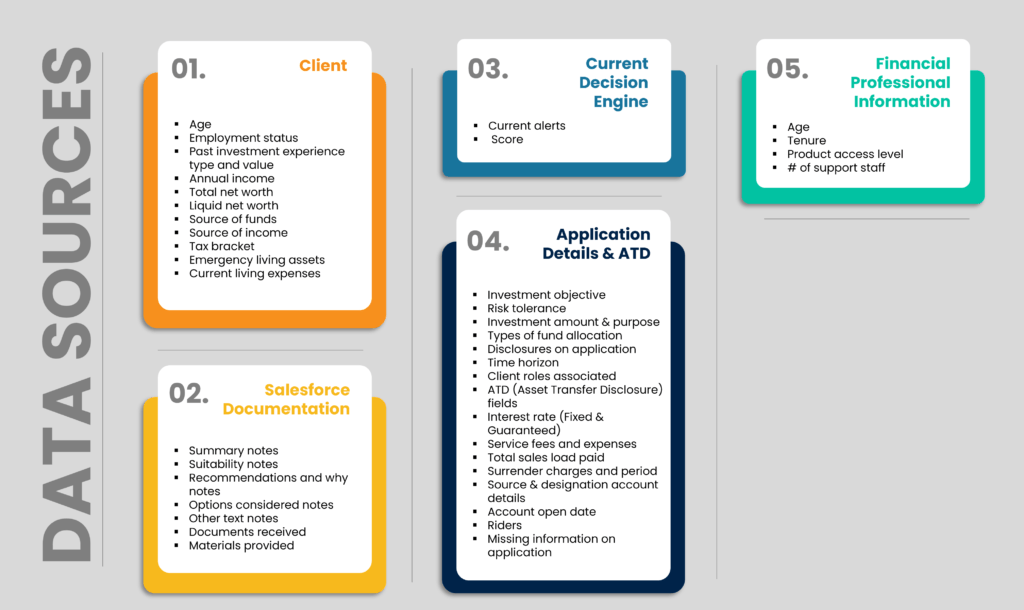
In most large enterprises today, we now have multiple sources of enterprise data – ranging from the Data Warehouse, Salesforce, PDF document dumps, etc. but the challenge is to pool all the data together. In this case, to enrich the set of data elements, our team used standard database connections to pull the data and collate it. Structured and unstructured data were present across different buckets:
- Client demographics such as age, income, and investment experience
- Details about the finance professional making the sale, such as tenure and history of past applications
- Details about the application, including investment objective, risk tolerance, expected portfolio composition, and suitability recommendation rationale.
Some of this data are structured fields, but others are free text which is complex to analyze.
To comply with regulators, explainable features had to be extracted from free text fields like the recommendation rationale. This is where NLP came in, helping extract structured information from free text for use in a subsequent model. Similarly, other NLP techniques were also used to extract information from text, resulting in the creation of features such as product suitability for the buyer and product recommendation by the finance professional.
The next step was to build a model which could classify a particular application as auto-approved or requiring follow-up. Several considerations could be indicative of approval, including:
- If the finance professional involved was tenured, there’s less likely to be a need for follow-up.
- If the source of the buyer’s funds was from multiple sources, follow-up is more likely.
- The more assets the buyer holds, the less likely follow-up is needed.
Classification models were built using data elements and extracted features representing these considerations. The methods included logistic regression – a statistical method that predicts the probability that the application should be approved; and tree-based models such as decision trees and random forests, which look to map combinations of the features to being auto-approved or not. While implementing a model with material consequences for customers’ money, it’s critical to ensure the model is well-tested on unseen scenarios. Therefore, the model was validated on multiple samples it had not been trained on. Additional business rules were also identified through the course of analysis.
The final system for approval combined both the existing rule engine and the analysis outputs. The AI model and identified business rules were deployed as a layer on top of the rule engine. Model outputs were explained using state-of-the-art methods such as Shapley Additive Explanations (SHAP). With this system, the company saw an improvement in auto-renewals by 29 percentage points (from 43% to 72). Our proprietary accelerators for solution development, such as TigerML and Blueprints, enabled the quick realization of value, helping wrangle the data and apply Machine Learning methods rigorously.
For a large enterprise, the low-hanging fruit for the application of AI is in augmenting rules. Another area is using NLP to extract information from the vast amounts of unstructured data available. Organizations that are part of a regulated industry (like financial services) must ensure that the models are explainable, using explainable features and methods like SHAP. This can unlock efficiency in a range of regulatory processes and have a direct impact on the bottom line.





