Azure Databricks and Azure Synapse are powerful analytical services that complement each other. But choosing the best-fit analytical Azure services can be a make-or-break moment. When done right, it ensures fulfilling end-user experiences while balancing maintainability, cost-effectiveness, security, etc.
So, let’s find out the considerations to pick the right one so that it helps deliver a complete solution to bridge some serious, prevalent gaps in the world of data analytics.
Delivering Tomorrow’s Analytical Needs Today
Nowadays, organizations’ analytical needs are vast and quite demanding in many aspects. For organizations of any size, it is vital to invest in platforms that deliver to these needs and are open enough, secure, cost-effective, and extendible. Some of these needs may include complex, time-consuming tasks such as:
- Integrating up to 500 single databases representing different source systems located in different domains and clouds into a single location, a Lakehouse, for instance.
- Processing terabytes or petabytes of data in batches and more frequently in near real-time.
- Training Machine Learning models on large datasets.
- Quickly performing explorative data analysis with environments provisioned on the fly.
- Quickly visualizing some business-related data and easily share it with a consumer community.
- Executing and monitoring thousands of pipelines daily in a scalable and cost-effective manner.
- Providing self-service capabilities around data governance.
- Self-optimizing queries over time.
- Integrating a comprehensive data quality processing layer into the Lakehouse processing.
- Easily sharing critical business data securely with peers or partner employees.
Why Azure Databricks Is Great for Enterprise-Grade Data Solutions
According to Microsoft Docs, Azure Databricks is defined as a unified set of tools for building, deploying, sharing, and maintaining enterprise-grade data solutions at scale. The Azure Databricks Lakehouse Platform integrates cloud storage and security in your cloud account and manages and deploys cloud infrastructure on your behalf.
From a developer’s point of view, Azure Databricks makes it easy to write Python, Scala, and SQL code and execute this code on a cluster to process the data – with many different features. We recommend reviewing the “used for” section of the above link for further details.
Azure Databricks originates from Apache Spark but has many specific optimizations that the open-source version of Spark doesn’t provide. For example, the Photon engine can speed up processing by up to 30 % without code optimization or refactoring.
Initially, Azure Databricks was more geared toward data scientists and ML workloads. However, over time Databricks added data engineering and general data analytics capabilities to the platform. It provides metadata management via a tool called “Unity,” which is a part of the Databricks platform. Azure Databricks also provides a data-sharing feature allowing secure data sharing across company boundaries.
Azure Databricks is extremely effective in ML processing with an enormous amount of ML libraries built in and its Data Engineering/ Lakehouse processing capabilities. Languages such as Python, Scala, and SQL are popular among data professionals – providing many APIs to interact and process data into any desired output shape.
Azure Databricks provides Delta Live Tables for developers to generate ingestion and processing pipelines with significantly lower effort. So, it is a major platform bound to see wider adoption as an integral part of any large-scale analytical platform.
How Azure Synapse Speeds Up Data-Driven Time-To-Insights
According toMicrosoft Docs, Azure Synapse is defined as an enterprise analytics service that accelerates time-to-insight across data warehouses and big data systems. Azure Synapse brings together the following:
- The best SQL technologies used in enterprise data warehousing.
- Spark technologies used for big data.
- Data Explorer for log and time series analytics.
- Pipelines for data integration and ETL/ELT.
- Deep integration with other Azure services such as Power BI, Cosmos DB & Azure ML.
Azure Synapse integrates several independent services like Azure Data Factory, SQL DW, Power BI, and others under one roof, called Synapse Studio. From a developer’s point of view, Azure Synapse Studio provides the means to write Synapse Pipelines and SQL scripts and execute this code on a cluster to process the data. It also easily integrates many other Azure Services into the development process.
Due to its deep integration with Azure, Azure Synapse effortlessly allows using other related Azure Services, such as Azure Cognitive Services and Cosmos DB. Architecturally, this is important since easy integration of capabilities is a critical criterion when considering platforms.
Azure Synapse shines in the areas of data and security integration. If existing workloads already use many other related Azure Services like Azure SQL, then integration is likely easier than other solutions. Synapse Pipelines can also act as an orchestration layer to invoke other compute solutions within Synapse or Azure Databricks.
This integration from Synapse Pipelines to invoke Databricks Notebooks will be a key area to review further in the next section.
It is vital to note that an integrated runtime is required for Synapse Pipelines to access on-premises resources or resources behind a firewall. This integrated runtime acts as an agent – enabling pipelines to access the data and copy them to a destination defined in the pipeline.
Azure Databricks and Azure Synapse: Better Together
As mentioned earlier (and shown in Image 1), Databricks Notebooks and the code included in the Notebooks Spark-SQL, Python, or Scala) can be invoked through ADF/Synapse Pipelines and therefore orchestrated. It is where Databricks and Synapse sync up great. In image 1, we show how a Synapse Pipeline looks like that moves data from Bronze to Silver.
When completed, it continues to process the data into the gold layer. It is just a basic pattern, and many more patterns can be implemented to increase the reuse and flexibility of the pipeline.
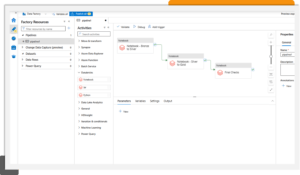
For instance, we can use parameters supplied from a configuration database (Azure SQL or similar) and have Synapse Pipelines pass the parameters to the respective Databricks Notebooks. It is for the parametrized execution of Notebooks – allowing for code reuse and reducing the time required to implement the solution.
Furthermore, the configuration database can supply source system connections and destinations such as databases or Databricks Lakehouses at runtime.
It is also possible to break down a large pipeline into multiple pieces and work with a Parent-Child pattern. The complete pipeline of several Parent—Child patterns could exist, one for each layer, just as an example. Defining these structures at the implementation’s beginning is vital to a maintainable and cost-effective system in the long run. Further abstractions can be added to increase code reuse and integrate a structured and effective testing framework.
While it is an additional effort to set up Azure Service (Databricks and Synapse), we recommend it as a good investment – especially for larger-scale analytical projects dealing with DE or ML-based workloads.
Also, providing technical implementation teams with options regarding the tooling and language the team would prefer for a given task. Typically, it positively impacts the timeline while reducing implementation risks.
Final Thoughts
You can easily take the ideas and concepts described here to build a metadata-driven data ingestion system based on Azure Databricks and Synapse.
These discussed concepts can also be applied to ML workloads using Databricks with ML Flow and Azure Synapse, and Azure ML.
Also, integrating Databricks Lakehouse and Unity is another crucial consideration in designing these solutions.
We hope this article gave some necessary insights on the power of Azure Databricks and Azure Synapse – and how they can be used to deliver modularized, flexible, and maintainable data ingestion and processing solutions.





