“Data is a precious thing and will last longer than the systems themselves.”– Tim Berners-Lee, inventor of the World Wide Web
Organizations spend a lot of time and effort building pipelines to consume and publish data coming from disparate sources within their Data Lake. Most of the time and effort in large data initiatives are consumed in data ingestion development.
What’s more, with an increasing number of businesses migrating to the cloud, factors like breaking data silos and enhancing data discoverability of data environments have become a business priority.
While Data Lake is the heart of data operations, one should carefully tie capabilities like data security, data quality, metadata-store, etc within the ecosystem.
Properties of an Enterprise Data Lake solution
In a large-scale organization, the Data Lake should possess these characteristics:
- Data Ingestion- the ability to consume structured, semi-structured, and unstructured data
- Supports push (batch and streaming systems) and pull (DBs, APIs, etc.) mechanisms
- Data security through sensitive data masking, tokenization, or redaction
- Natively available rules through the Data Quality framework to filter impurities
- Metadata Store, Data Dictionary for data discoverability and auditing capability
- Data standardization for common data format
A common reusable framework is needed to reduce the time and effort in collecting and ingesting data. At Tiger Analytics, we are solving these problems by building a scalable platform within AWS using AWS’s native services and open-source tools. We’ve adopted a modular design and loosely coupled multi-layered architecture. Each layer provides a distinctive capability and communicates with each other via APIs, messages, and events. The platform abstracts complex processes in the backend and provides a simple easy-to-use UI for the stakeholders
- Self-service UI to quickly configure data workflows
- Configuration-based backend processing
- AWS cloud native and open-source technologies
- Data Provenance: data quality, data masking, lineage, recovery and replay audit trail, logging, notification
Before exploring the architecture, let’s understand a few logical components referenced in the blog.
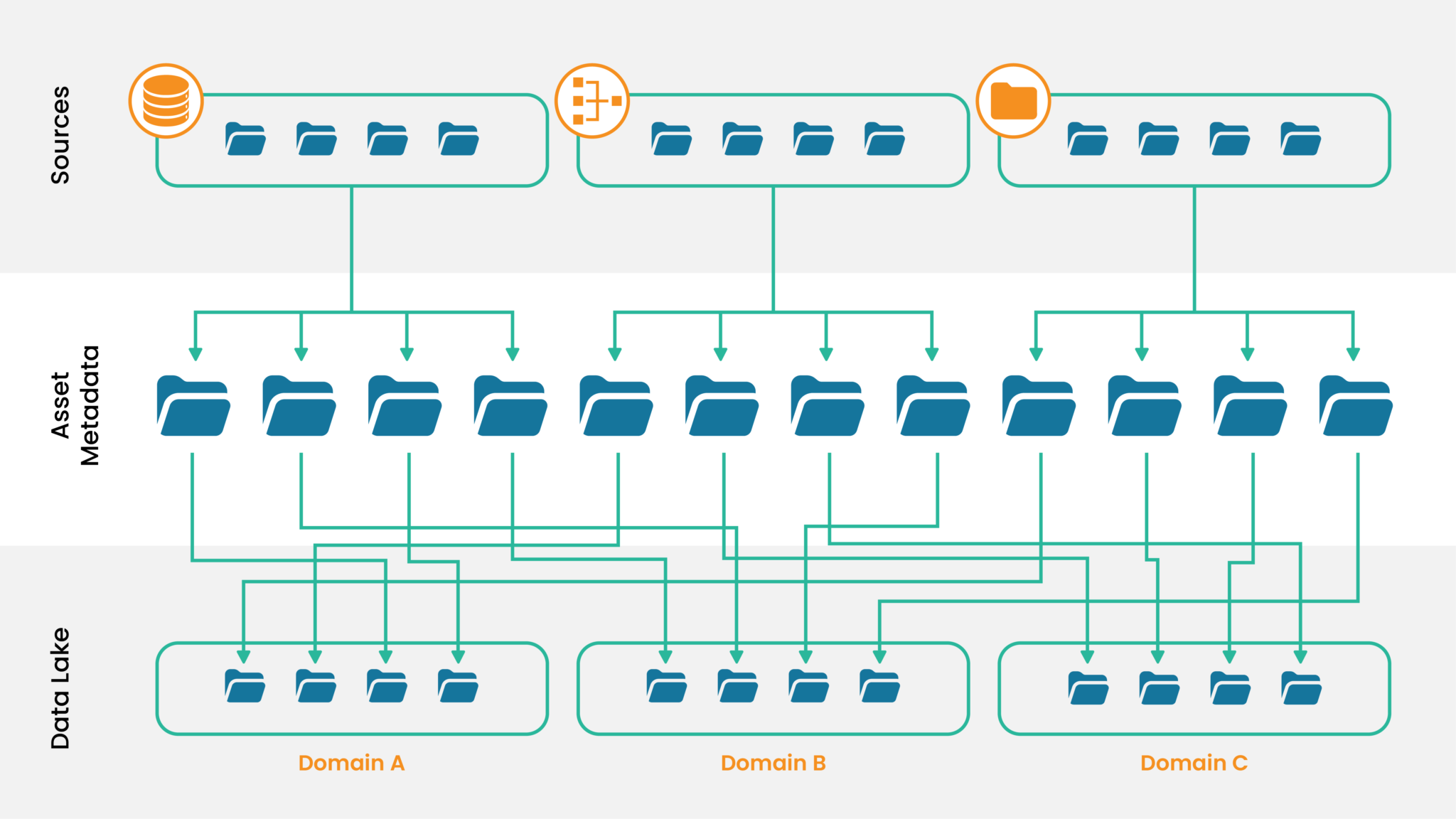
- Sources are individual entities that are registered with the framework. They align with systems that own one or more data assets. The system could be a database, a vendor, or a social media website. Entities registered within the framework store various system properties. For instance, if it is a database, then DB Type, DB URL, host, port, username, etc.
- Assets are the entries within the framework. They hold the properties of individual files from various sources. Metadata of source files include column names, data types, security classifications, DQ rules, data obfuscation properties, etc.
- Targets organize data as per enterprise needs. There are various domains/sub-domains to store the data assets. Based on the subject area of the data, the files can be stored in their specific domains.
The Design Outline
With the demands to manage large volumes of data increasing year on year, our data fabric was designed to be modular, multi-layered, customizable, and flexible enough to suit individual needs and use cases. Whether it is a large banking organization with millions of transactions per day and a strong focus on data security or a start-up that needs clean data to extract business insights, the platform can help everyone.
Following the same modular and multi-layered design principle, we, at Tiger, have put together the architecture with the provision of swapping out components or tools if needed. Keeping in mind that the world of technology is ever-changing and volatile we’ve built flexibility into the system.
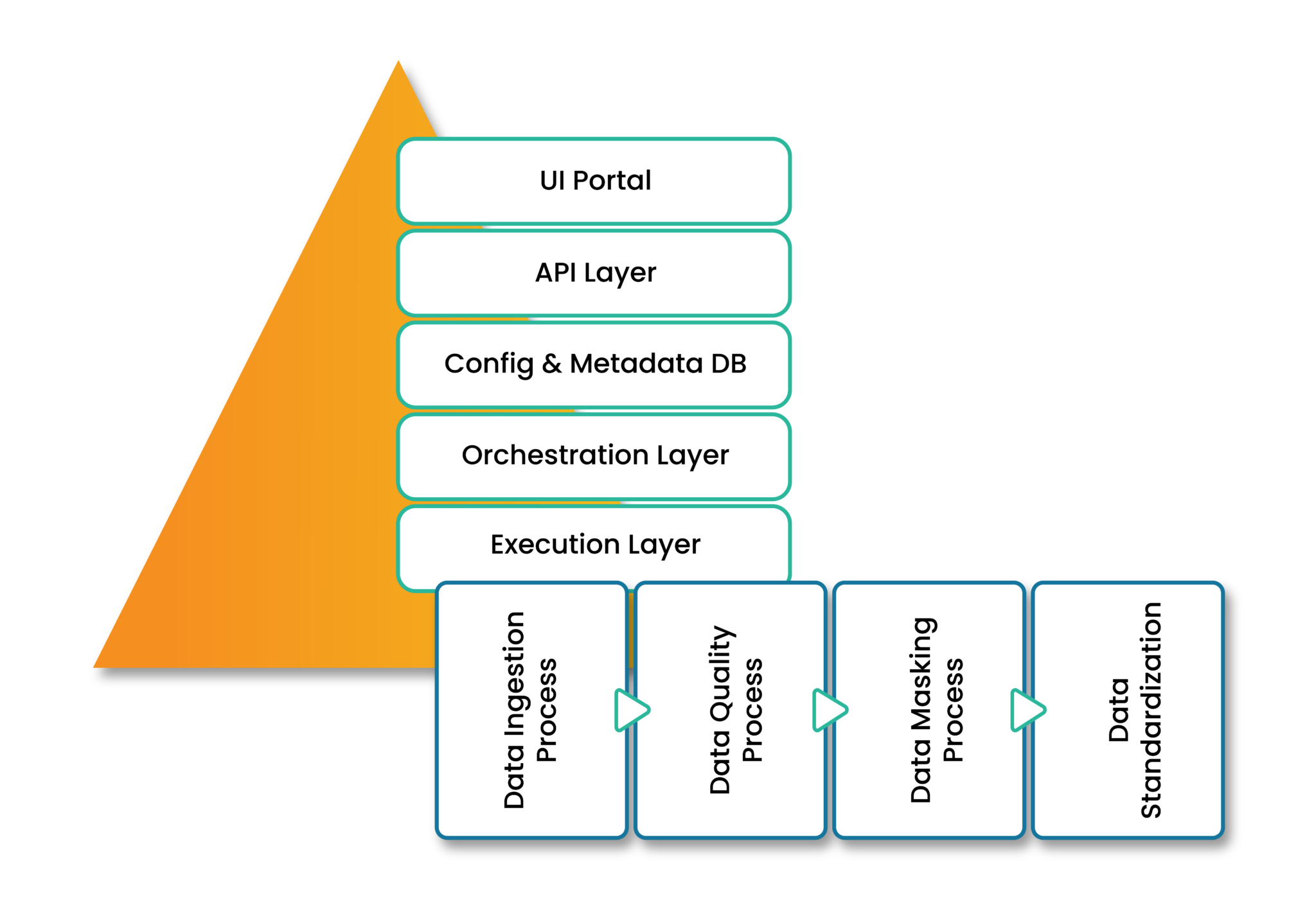
- UI Portal provides a user-friendly self-service interface to set up and configure sources, targets, and data assets. These elements drive the data consumption from the source to Data Lake. These self-service applications allow the federation of data ingestion. Here, data owners manage and support their data assets. Teams can easily onboard data assets without building individual pipelines. The interface is built using ReactJS with Material-UI, for high-quality front-end graphics. The portal is hosted on an AWS EC2 instance, for resizable compute capacity and scalability.
- API Layer is a set of APIs which invokes various functionalities, including CRUD operations and AWS service setup. These APIs create the source, asset, and target entities. The layer supports both synchronous and asynchronous APIs. API Gateway and Lambda functions provide the base of this component. Moreover, DynamoDB captures events requested for audit and support purposes.
- Config and Metadata DB is the data repository to capture the control and configuration information. It holds the framework together through a complex data model which reduces data redundancy and provides quick query retrieval. The framework uses AWS RDS PostgreSQL which natively implements Multiversion Concurrency Control (MVCC). It provides point-in-time consistent views without read locks, hence avoiding contentions.
- Orchestration Layer strings together various tasks with dependencies and relationships within a data pipeline. These pipelines are built on Apache Airflow. Every data asset has its pipeline, thereby providing more granularity and control over individual flows. Individual DAGs are created through an automated process called DAG-Generator. It is a python-based program tied to the API that registers data assets. Every time a new asset is registered, the DAG-Generator creates a DAG based on the configurations. Later, they are uploaded to the Airflow Server. These DAGs may be time-driven or event-driven, based on the source system.
- Execution Layer is the final layer where the magic happens. It comprises various individual python-based programs within AWS Glue jobs. We will be seeing more about this in the following section.
Data Pipeline (Execution Layer)
A data pipeline is a set of tools and processes that automate the data flow from the source to a target repository. The data pipeline moves data from the onboarded source to the target system.
- Data Ingestion
- Data Quality
- Data Obfuscation/Masking
- Data Standardization
Several patterns affect the way we consume/ingest data. They vary depending on the source systems and consuming frequency. For instance, ingesting data from a database requires additional capabilities compared to consuming a file dropped by a third-party vendor.
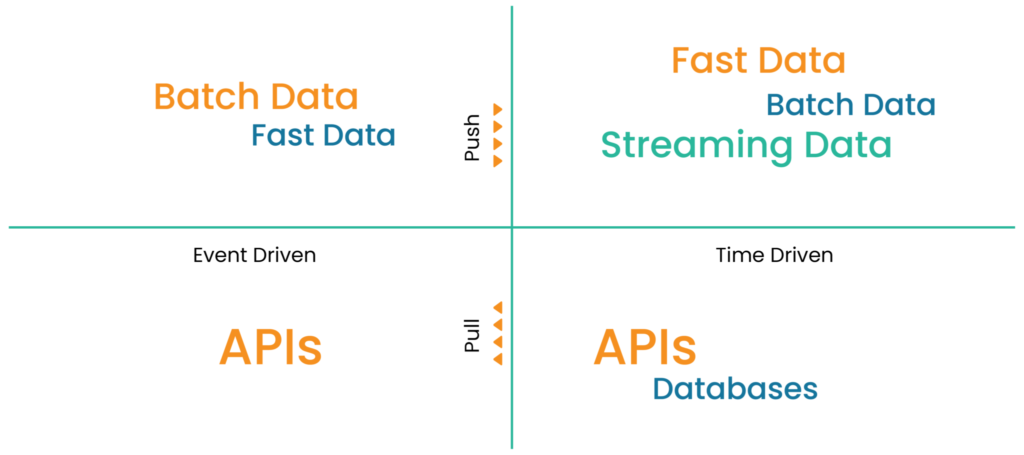
The Data Ingestion Quadrant is our base outline to define consuming patterns. Depending on the properties of the data asset, the framework has the intelligence to use the appropriate pipeline for processing. To achieve this, we have individual S3 buckets for time-driven and event-driven sources. Driver lambda function externally invokes event-driven Airflow DAGs and CRON expressions within DAGs invoke time-driven schedules.
These capabilities consume different file formats like CSV, JSON, XML, parquet, etc. Connector libraries are used to pull data from various databases like MySQL, Postgres, Oracle, and so on.
Data is the core component of any business operation. Data Quality (DQ) in any enterprise system determines its success. The data platform requires a robust DQ framework that promises quality data in enterprise repositories.
For this framework, we have the AWS open-source library called DEEQU. It is a library built on top of Apache Spark. Its Python interface is called PyDeequ. DEEQU provides data profiling capabilities, suggests DQ rules, and executes several checks. We have divided DQ checks into two categories:
– Default Checks are the DQ rules that automatically apply to the attributes. For instance, Length Check, Datatype Check, and Primary Key Check. These data asset properties are defined while registering in the system.
– Advanced Checks are the additional DQ rules. They are applied to various attributes based on the user’s needs. The user defines these checks and stores them in the metadata.
The DQ framework pulls these checks from the metadata store, and it identifies the default checks through data asset properties. Eventually, it constructs a bulk check module for data execution. DQ Results are stored in the backend database. The logs are stored in the S3 bucket for detailed analysis. DQ summary available in the UI provides additional transparency to business users.
Data masking is the capability of dealing with sensitive information. While registering a data asset, the framework has a provision to enable tokenization on sensitive columns. The Data Masking task uses an internal algorithm and a key (associated with the framework and stored in the AWS Secret Manager). It tokenizes those specific columns before storing them in the Data Lake. These attributes can be detokenized through user-defined functions. It also requires additional key access to control attempts by unauthorized users.
The framework also supports other forms of irreversible data obfuscation, such as Redaction and Data Perturbation.
Data standardization brings data into a common format. It allows data accessibility using a common set of tools and libraries. The framework executes standardized operations for data consistency. The framework can, therefore:
- Standardize target column names.
- Support file conversion to parquet format.
- Remove leading zeroes from integer/decimal columns.
- Standardize target column datatypes.
- Add partitioning column.
- Remove leading and trailing white spaces from string columns.
- Support date format standardization.
- Add control columns to target data sets.
Through this blog, we’ve shared insights on our generic architecture to build a Data Lake within the AWS ecosystem. While we can keep adding more capabilities to solve real-world problems, this is just a glimpse of data challenges that can be addressed efficiently through layered and modular design. You can use these learnings to put together the outline of a design that works for your use case while following the same core principles.





