Data lakes have long been pitched as the answer to common challenges, breaking down silos, simplifying data access, and providing a unified foundation for everything from analytics and reporting to machine learning and data science. They were scalable, flexible, and cost-effective platforms capable of handling any type of data, at any volume, from any source.
And in many ways, they delivered – up to a point.
As data volumes grew at an unprecedented scale and architectures became more distributed, many teams found that traditional data lakes, especially those built on early-generation formats like Parquet and ORC using classic approaches, were difficult to manage at scale. Issues like schema inflexibility, performance degradation, and coordination challenges across multiple engines often start to surface. These aren’t failures of the data lake concept itself, but signs that the foundational tooling needs to evolve. The data lake market value is projected to hit $80.2 billion by 2032.
At Tiger Analytics, we explored modern open table formats to address these limitations. The most widely adopted format for large-scale analytics is Apache Iceberg. Originally developed at Netflix, Apache Iceberg helps manage large datasets more reliably by introducing features like versioning, hidden partitioning, and metadata-based query pruning. Iceberg is also engine-agnostic and integrates with tools like Spark, Flink, Trino, and Hive. Iceberg is projected to become a standard for hybrid data lakes (on-prem and cloud combined), with over 60% of Fortune 500 companies reportedly testing it.
Based on our experience working with Iceberg across domains, we’ve developed a handy guide for data platform engineers, architects, and analytics leaders who are evaluating how to modernize their data lake stack. This guide breaks down practical use cases for Iceberg, how it works, optimization tips to get the most out of it, and a key case study from our work with a global insurer to illustrate how Iceberg can drive measurable improvements in data performance and manageability.
Real-world Apache Iceberg use cases for reliable data management
Apache Iceberg is a fundamentally new approach to data management, treating data like code. Instead of relying on static file structures and manual coordination, Iceberg organizes data into versioned snapshots, enabling atomic changes, rollbacks, and time travel. Each write operation generates a new snapshot, and changes can be validated before being published, similar to CI/CD pipelines in software development. Major companies like Netflix, Apple, LinkedIn, and Stripe use Iceberg to manage petabytes of data with minimal support costs.
Below are the common use cases for modern table formats like Iceberg mapped to the traditional data lake challenges they solve:
- Managing schema changes without data duplication:Traditional approaches like Hive often require recreating a table entirely to change its schema, which generates data copies. Duplication leads to paying for multiple copies of the same data and analysts spending hours searching for the correct version. The problem stems from a lack of ACID transactions.
Iceberg solves this through snapshot isolation, wherein schema changes are atomic, and readers only see complete versions of the data. ACID transactions in Iceberg ensure that even with dozens of processes running in parallel, data remains consistent. If two processes try to modify the same data, one will receive an error and must retry, acting like Git for data where you can always roll back to a previous version. Iceberg guarantees atomic operations, even when dozens of files are overwritten under the hood.
- Simplifying partition management in large-scale data lakes: A data lake with millions of small files (e.g., 10 MB) slows down simple queries. In Hive, partitioning requires explicitly specifying fields, while adding a new dimension later requires rewriting all data. Manual partitioning (creating folders like /year=2025/month=01) is a major challenge when scaling.
Iceberg implements hidden partitioning, where you specify partitioning rules once (e.g., days(timestamp)), and the system automatically sorts data during writing. It creates invisible structures, so you no longer manually create date-based folders, and queries read only relevant partitions. Thus, partition management evolves from manual creation of folders to simply setting a rule once.
- Making schema changes without full table rewrites:Parquet and ORC offer strong performance for many workloads, but schema changes, such as adding new columns, can introduce compatibility issues. For instance, reading older files that don’t include a newly added column may lead to errors like NullPointerException, unless the query engine includes safeguards to handle mixed schema versions gracefully.
Iceberg supports schema evolution, wherein you can add, rename, or remove columns, and the engine automatically adapts old data to the new schema. For instance, if a user_rating field is added, Iceberg will substitute NULL when reading files without it, preventing pipeline crashes. Adding a column becomes a simple ALTER TABLE command, and the system automatically adapts older data.
- Ensuring data consistency with concurrent writes:Traditional data lakes often lack built-in consistency checks and transactional guarantees, which means simultaneous writes or updates can conflict, leading to issues like partial overwrites, inconsistent reads, or lost data if coordination isn’t handled externally.
Iceberg introduces a snapshot mechanism in which each write creates a new snapshot of the data. Conflicts are controlled through optimistic locks. It acts like ‘Git for data’, allowing users to roll back to a previous version.
- Speeding up queries through smart file pruning:Traditional data lakes often require scanning large volumes of files to execute even simple queries, particularly when filtering on high-cardinality fields like user IDs or timestamps. This leads to inefficient use of compute resources. Iceberg addresses this through metadata pruning. It stores statistics such as min/max values for each file and uses them to eliminate irrelevant files before reading any data. For example, a query filtering by user_id first checks these metadata stats and reads only the matching files. Combined with support for vectorized execution, which processes data in batches instead of one row at a time, Iceberg significantly improves query performance and resource utilization.
- Avoiding vendor lock-in in multi-cloud architectures: Managing data across cloud environments can be challenging, especially when metadata is locked into proprietary systems tied to a specific vendor. This often complicates migrations and limits flexibility. Iceberg addresses this by storing all metadata as open, portable files in object storage (like S3 or GCS). As a result, migrating a data lake from AWS to Google Cloud becomes a matter of copying files, without retooling pipelines or introducing downtime. Because Iceberg is open-source and engine-agnostic, it avoids vendor lock-in while supporting consistent access across clouds.
A quick dive into Iceberg’s architectural components
When comparing the two, Iceberg is akin to searching for a book using a well-organized catalog, while traditional formats are like searching without one. Its architecture is based on a three-tier structure where metadata is key.
- The first tier is a catalog, stored directly in object storage (S3, GCS). It contains information about schemas, partitions, and data versions, acting as a dynamic map for finding data. When querying data for a specific period, the system first accesses the catalog to find relevant files.
- The second tier consists of manifests, which store statistics like minimum/maximum values and row counts. This data allows pruning of up to 90% of unnecessary files during query planning.
- The third tier contains the data files themselves (Parquet, ORC), but with guaranteed consistency and atomicity provided by Iceberg’s management layers.
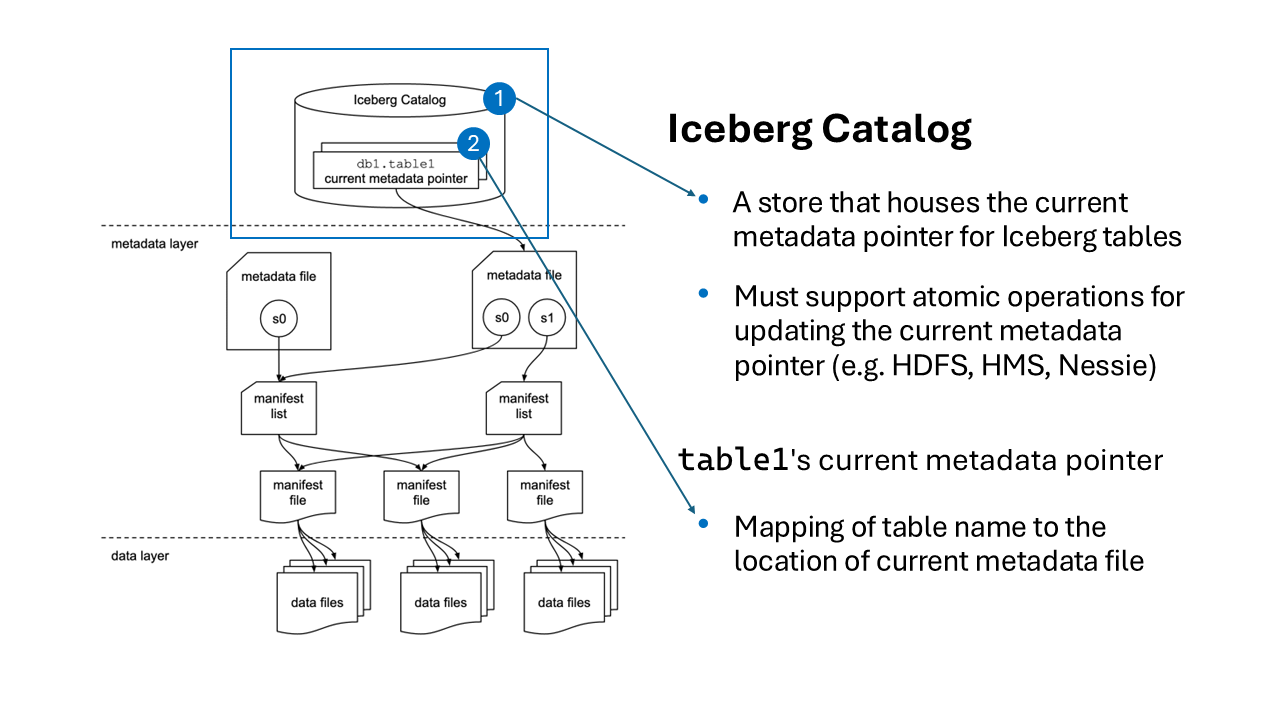
Caption: An overview of Apache Iceberg architecture (Source: Dremio)
BigQuery and Redshift vs Iceberg: Which solution fits your data strategy?
While managed data warehouses like BigQuery and Redshift offer fast setup and seamless SQL analytics with strong native optimizations, they come with trade-offs in flexibility and cloud dependency. As covered earlier, Iceberg provides open-source, engine-agnostic table management with strong ACID guarantees and multi-cloud portability, ideal for complex, evolving data environments.
Consider BigQuery or Redshift when your team requires:
- Rapid deployment and fully managed infrastructure
- Deep integration with their respective cloud ecosystems
- Standard SQL analytics workloads with less emphasis on cross-cloud data portability
How to identify if you need to switch to Apache Iceberg
Deciding whether to implement Iceberg depends on your infrastructure’s maturity and the urgency of the problems it solves. Iceberg is likely worth considering if:
- You face uncontrolled data volume growth, and existing solutions (Hive, Hudi) can’t match the required performance and consistency.
- You need strong ACID transaction guarantees for data reliability, especially with concurrent writes and updates.
- Analyses of historical data and easy rollback to previous versions are required without data duplication.
- You use open-source engines like Spark, Flink, Kafka, or Trino and want consistent data access while reducing dependence on cloud providers.
If these issues are current bottlenecks, Iceberg can help improve performance and data manageability.
Modernization in action – How Tiger Analytics helped a leading insurer enhance data analysis and management
A leading insurance provider was looking to optimize the management and analysis of petabyte-scale datasets. These datasets were characterized by highly complex schemas reflecting diverse insurance products, customer interactions, claims, and regulatory requirements.
Identifying the business needs
The client relied on multiple query engines (e.g., Spark, Flink, Trino, and Hive) to process claims, policy, and customer data for reporting, risk modeling, and predictive analytics. The legacy data lake, built on HDFS-based tables, couldn’t match the growing need for scalability, query performance, and schema management, prompting the adoption of Apache Iceberg to modernize the data platform. Below is a quick snapshot of the target issues:
- Scalability issues with large datasets
- Complex schema evolution
- Query performance bottlenecks
- Multi-engine compatibility
- Cost and resource inefficiency
Developing the solution
The insurer partnered with us to design and implement a comprehensive solution based on Apache Iceberg’s advanced table format to address these challenges. The solution could be broken down into five key components:
- Migration to Apache Iceberg: All legacy HDFS-based tables were migrated to Iceberg-managed tables in a phased manner to minimize downtime. This allowed the organization to retain existing data while gaining access to Iceberg’s advanced versioning and transactional capabilities.
- Hidden Partitioning: We implemented Iceberg’s hidden partitioning strategy to simplify query planning and reduce the operational overhead of manually managing thousands of date- or region-based folders, enabling more efficient writes and reads without requiring explicit filters or restructuring.
- Optimized Metadata Management: To accelerate query performance, we leveraged Iceberg’s manifest and metadata layers, which store detailed statistics. This allowed for aggressive file pruning during query planning, which significantly reduced the volume of data scanned, a critical function for petabyte-scale claims and policy datasets.
- Multi-Engine Integration: The solution allowed for multi-engine compatibility, which minimized coordination issues, streamlined schema management, and ensured that data remained consistent regardless of the engine or workload accessing it.
- Performance Optimization: Iceberg’s ability to prune files and partitions based on metadata was used to minimize data scans. For example, queries targeting specific policy types or date ranges only accessed relevant Parquet files, reducing I/O costs. Compaction jobs were scheduled to optimize file sizes and reduce fragmentation, further improving query performance.With the adoption of Apache Iceberg, the insurer transformed its data lake into a high-performance, scalable, and cost-efficient platform. The solution brought about a nearly 50% reduction in I/O costs, compared to HDFS-based tables, for queries targeting specific partitions or columns. We also observed a 40% to 50% reduction in query latency when running complex aggregations on larger datasets. These optimizations, combined with flexible schema evolution and efficient storage management, enhanced both system performance and analyst productivity.
Iceberg optimization strategies to maximize performance
In our work, we have identified four key practices that can optimize Iceberg performance:
- Hidden Partitioning: Using constructs like PARTITIONED BY days(event_time) effectively distributes data
- Z-Order: Useful for high-cardinality columns (like user IDs or geodata) to speed up equality queries by 50% to 70%
- File Compaction: Regularly running the OPTIMIZE operation combines small files into larger blocks (128 MB+) to combat poor performance caused by millions of small files
- Write-Audit-Publish (WAP): Writing data to draft tables, pre-checking quality, then publishing to production helps prevent ‘garbage’ data from affecting analytics and reporting quality.
Understanding the potential limitations when implementing Iceberg at scale
Despite its advantages, implementing Iceberg requires a nuanced approach to combat its limitations, a few of which are mentioned below:
- Setup complexity: Configuring Iceberg, especially for multi-cloud environments (S3 and GCS simultaneously), requires a high level of expertise in distributed computing and storage and can take significant time.
- Resource intensity: Iceberg is a resource-intensive solution, requiring powerful clusters. Compacting data can require twice as many resources compared to systems like Delta Lake.
- Functionality limitations: Iceberg doesn’t support indexing out of the box like systems such as Hudi, which can impact performance on queries with large data volumes.
Iceberg is developing solutions to address some of the above-mentioned limitations. For instance, integration with streaming systems like Apache Pulsar and Kafka for real-time analytics, improvements in automatic file optimization processes, and the introduction of AI-driven approaches for dynamic data partitioning.
Future-proofing data infrastructure with open table formats
Modern data formats are reshaping analytical infrastructure with features like schema evolution, ACID transactions, metadata-driven optimization, and cross-engine compatibility, having become a necessity for scalable, cloud-native platforms. Open table formats such as Apache Iceberg are part of a broader movement toward modular, interoperable architectures that meet the demands of data complexity without locking teams into vendor-specific workflows. As data systems evolve to support advanced analytics, AI, and hybrid cloud strategies, the formats that manage that data must evolve just as fast.
References
https://www.dremio.com/resources/guides/apache-iceberg-an-architectural-look-under-the-covers/
https://www.gminsights.com/industry-analysis/data-lake-market
https://medium.com/airbnb-engineering/upgrading-data-warehouse-infrastructure-at-airbnb-a4e18f09b6d5
https://netflixtechblog.com/optimizing-data-warehouse-storage-7b94a48fdcbe
https://www.youtube.com/watch?v=PKrkB8NGwdY&t=1544s&ab_channel=Dremio




