Today, most large enterprises collect huge amounts of data in various forms – structured, semi-structured, and unstructured. While Enterprise Data Warehouses are ACID compliant and well-suited to BI use cases, the kind of data that is collected today for ML use cases require much more flexibility in data structure and much more scalability in data volume than they can currently provide
The initial solution to this issue came with advancements in cloud computing and the advent of data lakes in the late 2010s. Lakes are built on top of cloud-based storage such as AWS S3 buckets and Azure Blob/ADLS. They are flexible and scalable, but many of the original benefits, such as ACID compliance, are lost.
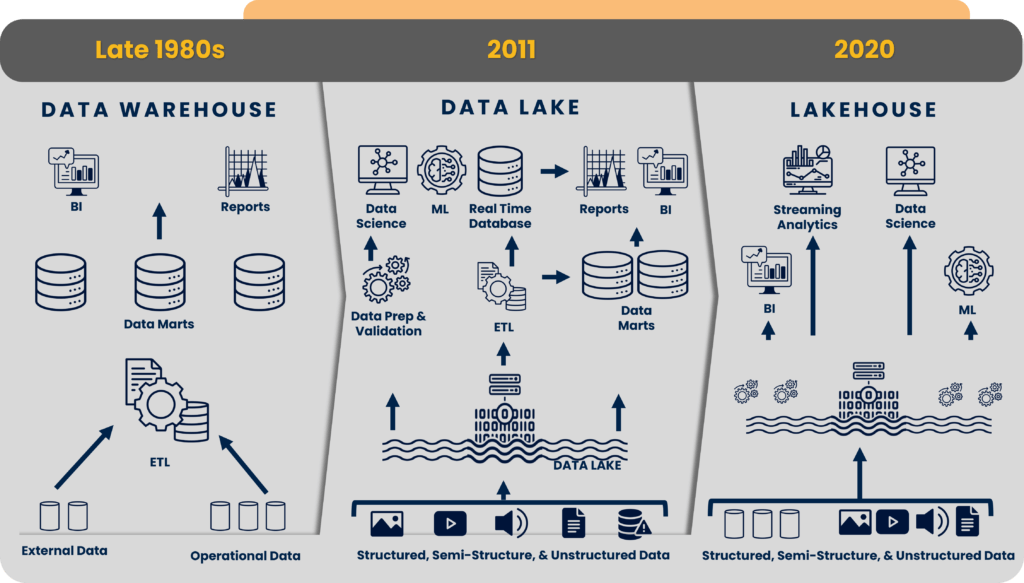
Data Lakehouse has evolved to address this gap. A Data Lakehouse combines the best of Data Lakes and Data Warehouses – it has the ability to store data at scale while providing the benefits of structure.
At Tiger Analytics, we’ve worked across cloud platforms like AWS, GCP, Snowflake, and more to build a Lakehouse for our clients. Here’s a comparative study of how to implement a Lakehouse pattern across major available platforms.
Questions you may have:
All the major cloud platforms in the market today can be used to implement a Lakehouse pattern. The first question that comes to mind is – how do they compare, i.e., what services are available across different stages of the data flow? The next – Given many organizations are moving toward a multi-cloud setup, how do we set up Lakehouses across platforms?
Finding the right Lakehouse architecture
Given that the underlying cloud platform may vary, let’s look at a platform-agnostic architecture pattern, followed by details of platform-specific implementations. The pattern detailed below enables data ingestion from a variety of data sources and supports all forms of data like structured (tables, CSV files, etc.), semi-structured (JSON, YAML, etc.), and unstructured (blobs, images, audio, video, PDFs, etc.).
It comprises four stages based on the data flow:
1. Data Ingestion – To ingest the data from the data sources to a Data Lake storage:
- This can be done using cloud-native services like AWS DMS, Azure DMS, GCP Data Transfer service or third-party tools like Airbyte or Fivetran, etc.
2. Data Lake Storage – Provide durable storage for all forms of data:
- Options depend on the Cloud service providers. For example – S3 on AWS, ADLS/Blob on Azure, and Google Cloud storage on GCP, etc.
3. Data Transformation – Transform the data stored in the data lake:
- Languages like Python, Spark, Pyspark & SQL can be used based on requirements.
- Data can also be loaded to the data warehouse without performing any transformations.
- Services like AWS Glue Data Studio and GCP Data Flow provide workflow based/no-code options to load the data from the data lake to the data warehouse.
- Transformed data can then be stored in the data warehouse/data marts.
4. Cloud Data Warehouse – Provision OLAP with support for Massive Parallel Processing (MPP) and columnar data storage:
- Complex data aggregations are made possible with support for SQL querying.
- Support for structured and semi-structured data formats.
- Curated data is stored and made available for consumption by BI applications/data scientists/data engineers using role-based (RBAC) or attribute-based access controls (ABAC).

Let’s now get into the details of how this pattern can be implemented on different cloud platforms. Specifically, we’ll look at how a lakehouse can be set up by migrating from an on-premise data warehouse or other data sources by leveraging cloud-based warehouses like AWS Redshift, Azure Synapse, GCP Big query, or Snowflake.
How can a Lakehouse be implemented on different cloud platforms?
Lakehouse design using AWS
We deployed an AWS-based Data Lakehouse for a US-based Capital company with a Lakehouse pattern consisting of:
- Python APIs for Data Ingestion
- S3 for the Data Lake
- Glue for ETL
- Redshift as a Data Warehouse
Here’s how you can implement a Lakehouse design using AWS
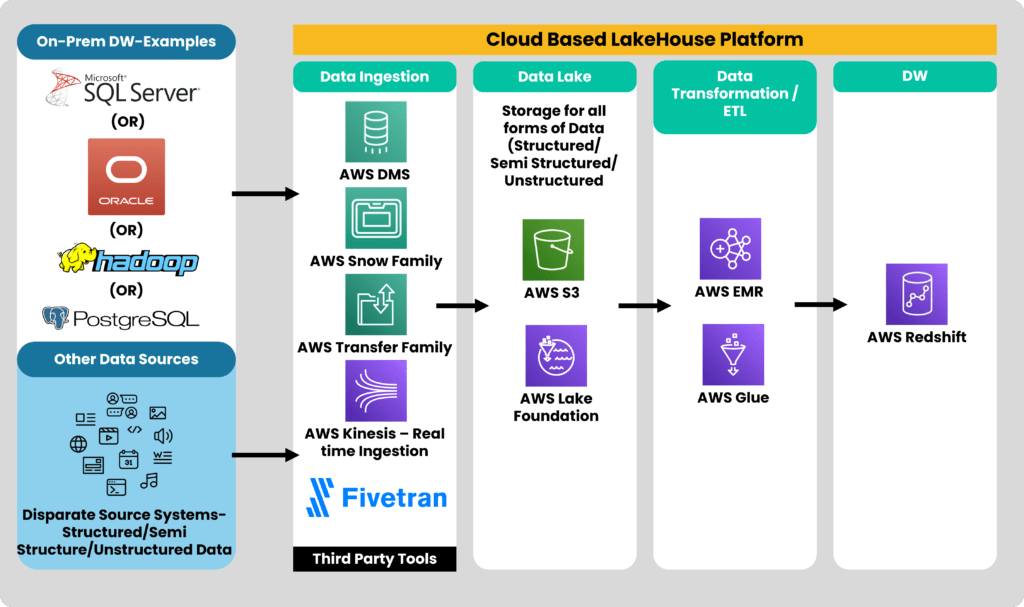
1. Data Ingestion:
- AWS Database Migration Service to migrate data from the on-premise data warehouse to the cloud.
- AWS Snow family/Transfer family to load data from other sources.
- AWS Kinesis (Streams, Firehose, Data Analytics) for real-time streaming.
- Third-party tools like Fivetran can also be used for moving data.
2. Data Lake:
- AWS S3 as the data lake to store all forms of data.
- AWS Lake Formation is helpful in creating secured and managed data lakes within a short span of time.
3. Data Transformation:
- Spark-based transformations can be done using EMR or Glue.
- No code/workflow-based transformations are done using Glue Data Studio/Glue Databrew. Third-party tools like DBT can also be used.
4. Data Warehouse:
- AWS Redshift as the data warehouse which supports both structured (table formats) and semi-structured data (SUPER datatype).
Lakehouse design using Azure
One of our clients was an APAC-based automotive company. After evaluating their requirements, we deployed a Lakehouse pattern consisting of:
- ADF for Data Ingestion
- ADLS Gen 2 for the Data Lake
- Databricks for ETL
- Synapse as a Data Warehouse
Let’s look at how we can deploy a Lakehouse design using Azure
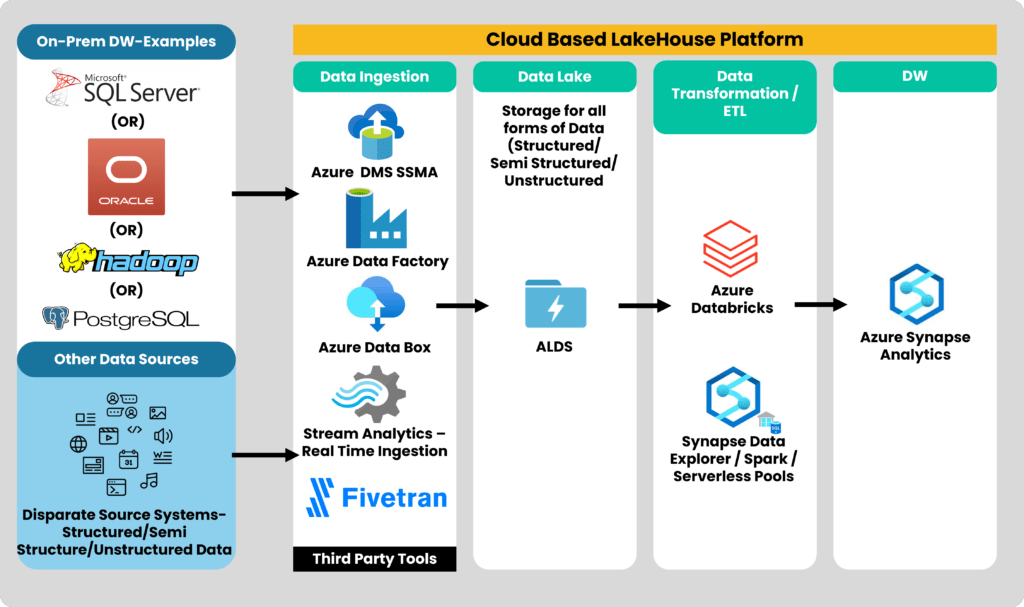
1. Data Ingestion:
- Azure Database Migration Service and SQL Server Migration Assistant (SSMA) to migrate the data from an on-premise data warehouse to the cloud.
- Azure Data Factory (ADF) and Azure Data Box can be used for loading data from other data sources.
- Azure stream analytics for real-time streaming.
- Third-party tools like Fivetran can also be used for moving data.
2. Data Lake:
- ADLS as the data lake to store all forms of data.
3. Data Transformation:
- Spark-based transformations can be done using Azure Databricks.
- Azure Synapse itself supports various transformation options using Data Explorer/Spark/Serverless pools.
- Third-party tools like Fivetran can also be used for moving data. Third-party tools like Fivetran are also an option.
4. Data Warehouse:
- Azure Synapse as the data warehouse.
Lakehouse design using GCP
Our US-based retail client needed to manage large volumes of data. We deployed a GCP-based Data Lakehouse with a Lakehouse pattern consisting of:
- Pub/sub for Data Ingestion
- GCS for the Data Lake
- Data Proc for ETL
- BigQuery as a Data Warehouse
Here’s how you can deploy a Lakehouse design using GCP
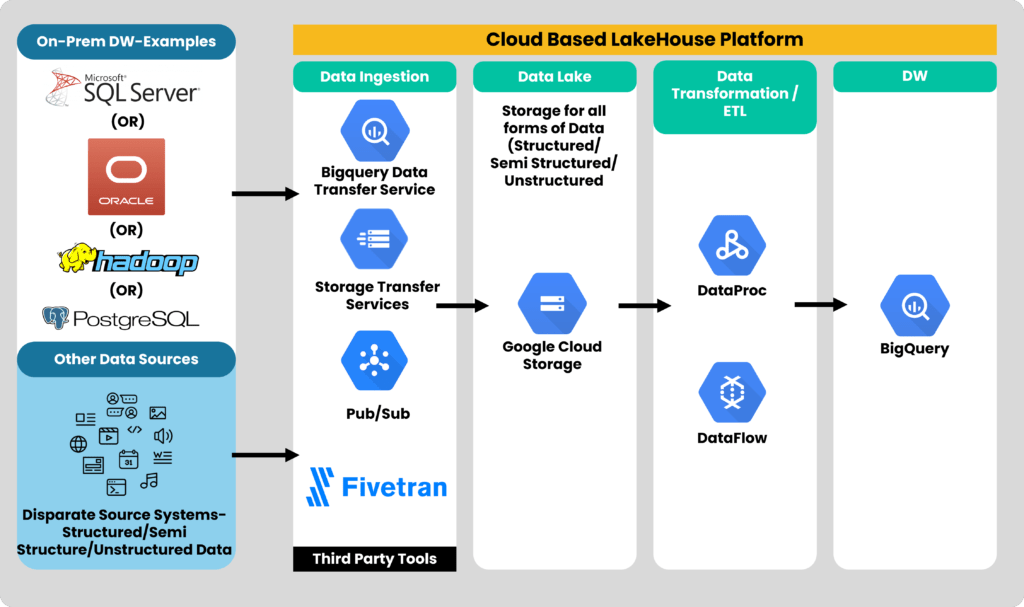
1. Data Ingestion:
- BigQuery data transfer service to migrate the data from an on-premise data warehouse to the cloud.
- GCP Data Transfer service can be used for loading data from other sources.
- Pub/Sub for real-time streaming.
- Third-party tools like Fivetran can also be used for moving data.
2. Data Lake:
- Google Cloud Storage as the data lake to store all forms of data.
3. Data Transformation:
- Spark based transformations can be done using Dataproc.
- No code/workflow-based transformations are done using DataFlow. Third party tools like DBT can also be used.
4. Data Warehouse:
- GCP BigQuery as the data warehouse which supports both structured and semi-structured data.
Lakehouse design using Snowflake:
We successfully deployed a Snowflake-based Data Lakehouse for our US-based Real estate and supply chain logistics client with a Lakehouse pattern consisting of:
- AWS native services for Data Ingestion
- AWS S3 for the Data Lake
- Snowpark for ETL
- Snowflake as a Data Warehouse
Here’s how you can deploy a Lakehouse design using Snowflake
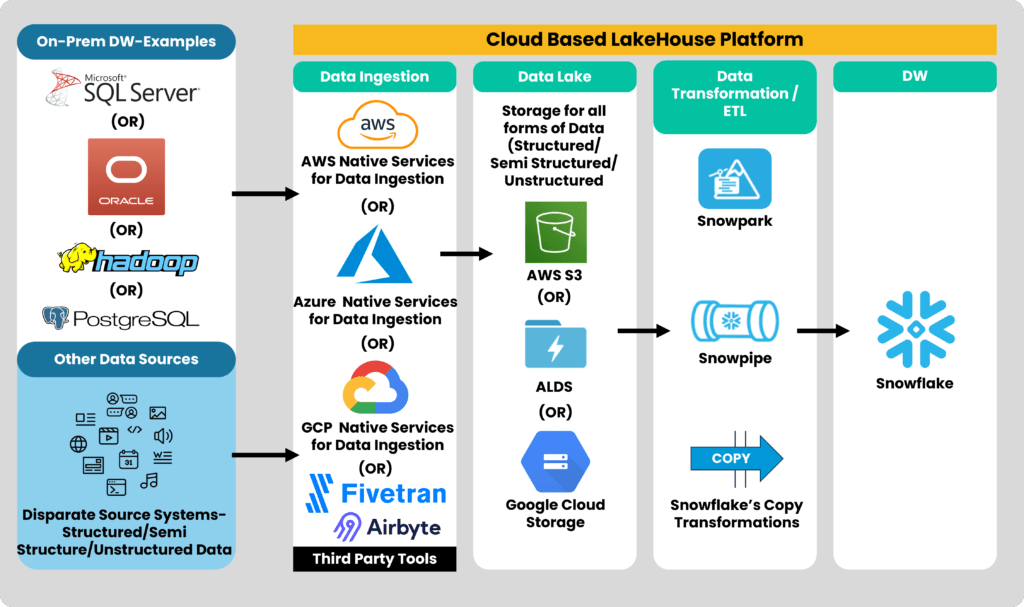
Implementing a lakehouse on Snowflake is quite unique as the underlying cloud platform could be any of the big 3 (AWS, Azure, GCP), and Snowflake can run on top of it.
1. Data Ingestion:
- Cloud native migration services can be used to store the data on the respective cloud storage.
- Third party tools like Airbyte and Fivetran can also be used to ingest the data.
2. Data Lake:
- Depends on the cloud platform: AWS – S3, Azure – ADLS and GCP – GCS.
- Data can also be directly loaded onto Snowflake. However, a data lake storage is needed to store unstructured data.
- Dictionary tables can be used to catalog the staged files in cloud storage.
3. Data Transformation:
- Spark-based transformations can be done using Snowpark with support for Python. Snowflake natively supports some of the transformations while using the copy command.
- SnowPipe – Supports transformations on streaming data as well.
- Third-party tools like DBT can also be leveraged.
4. Data Warehouse:
- Snowflake as the data warehouse which supports both structured (table formats) and semi-structured data (VARIENT datatype). Other options like internal/external stages can also be utilized to reference the data stored on cloud-based storage systems.
Integrating enterprise data into a modern storage architecture is key to realizing value from BI and ML use cases. At Tiger Analytics, we have seen that implementing the architecture detailed above has streamlined data access and storage for our clients. Using this blueprint, you can migrate from your legacy data warehouse onto a cloud-based lakehouse setup.





