Imagine trying to translate a sentence between two languages. Even if you speak both fluently, some words have multiple meanings, and context determines which is correct. Now multiply this challenge across dozens of teams in a global enterprise, each building data products that are meant to feed AI systems. The same data can tell very different stories depending on who consumes it. In practice, the definition of metrics like revenue, customer engagement, or product performance can vary slightly across functions, even within the same company. These nuances are functional and semantic. Without a shared understanding, AI models can misinterpret inputs, deliver wrong insights, and widen the trust gap for business users.
This is one of the key challenges we help our partners, across industries, solve at Tiger Analytics. Our approach isn’t faster pipelines or bigger models, rather we present a structured framework that aligns data, context, and user needs. By embedding industry and domain knowledge into data product design, organizations can ensure that data is interpretable, actionable, and truly AI-ready.
Challenges in Scaling Data Products
Over the past few years, the number of data products – modular, reusable assets that bring data, logic, and business context together – built and harnessed by enterprises across industries has grown manifold. From what we’ve observed, the most common workflow looks something like this: pick a use case, build the data, integrate AI, and deliver quick wins that demonstrate potential value. While the use case-based approach does deliver quick wins, it can introduce technical complexity that only grows exponentially as more data products are created.
Without a clear roadmap for integrating AI and AI agents into business processes, teams often generate large volumes of analytical data that can be fragmented or inconsistently structured. Existing data may be difficult to fully interpret, with key knowledge concentrated in a few custodians. Limited guardrails and observability can make it challenging to maintain confidence in data quality and analytical results. Another key challenge is accurately monitoring resource usage and consumption, leading to higher operational costs. Automated decisions may be met with skepticism if validation is unclear, and without consistent measurement, tracking the actual business value generated by AI initiatives can be difficult.
Together, these challenges highlight the need for a more cohesive approach to designing, connecting, and governing data products at scale. We believe building data products by blending three architectural pillars: data products, data mesh, and the lakehouse addresses key challenges:
- Data products are living, governed, ready-to-use assets. They bundle the data itself with rich metadata, KPIs, lineage, and governance controls around privacy, access, and contracts. By design, they are discoverable, contextualized, and reusable, enabling teams to leverage the same trusted data across multiple use cases, reducing duplication, accelerating insights, and lowering costs.
- Data mesh is an architectural pattern that requires organizational change. Its value comes from multi-disciplinary teams that both publish and consume data products, backed by a federated governance model. The core ideas of data domains, self-serve platforms, and clear ownership ensure that data becomes an interoperable, enterprise-wide asset rather than a collection of silos.
- Lakehouses combine the best of data lakes and warehouses, providing a high-performance, scalable platform that hosts both raw and curated datasets. When paired with a medallion architecture, data flows progressively from Bronze (raw) to Silver (refined) to Gold (business-ready), continuously improving structure, quality, and usability along the way.
These pillars form the foundation for blueprints like the Tiger Analytics Industry Domain Framework.
Tiger Analytics Industry Domain Framework: A Connected Blueprint for Modern Data Products
Building on Zhamak Dehghani’s data mesh principles, a well-constructed data product must be:
- Self-describing: Schemas, definitions, and business context are explicit so anyone can understand the data. For example, a revenue metric includes embedded definitions, calculation logic, acceptable usage notes, and links to upstream sources, so both analysts and AI systems interpret it consistently.
- Addressable: Data is discoverable and easy to locate. In practice, this means data products and metrics are searchable through a catalog, clearly tagged by domain and use case, and exposed via stable identifiers that consumers can reliably reference.
- Trustworthy: Quality rules and validation ensure accuracy and reliability. For instance, automated checks validate freshness, completeness, and threshold breaches, with quality scores and lineage surfaced to consumers before the data is used in analytics or AI workflows.
- Secure and governed: Classification, access controls, and policies protect sensitive information while enabling compliance. Sensitive attributes are tagged, access is role-based, and usage is governed by policies that enforce privacy and regulatory requirements without blocking legitimate business use.
The fundamental questions every organization must ask when building a data product are: Who is this product being designed for? How will they use it? What will they use it for? Who is creating it? What do data quality rules mean for the producer and the consumer? Even the most sophisticated technical build will fail if the product doesn’t resonate with its intended audience.
Based on our deep industry experience, we’ve designed a framework that bridges this gap. At its core, this framework is a blueprint for building connected data products imbued with industry and domain context: a comprehensive repository of use cases, analytical products, and associated metrics, mapped to an underlying connected data model, business rules, and lineage. It provides a ready-to-adopt starter pack of data products that support a variety of use cases such as revenue management, media mix modeling, pricing optimization and more, while remaining configurable for organization-specific requirements.
Here are the key design principles and associated operational pillars that make up the Tiger Analytics Industry Domain Framework:
Domain Design
Domain design forms the foundation of a scalable, enterprise-wide data product ecosystem. Enterprise data is decomposed by business functions (Sales, Finance, HR), lines of business, or regions, with clear ownership for quality, governance, and lifecycle management each owning their data and metrics. Each domain owns its data products and metrics end to end, ensuring accountability from creation through consumption. These domains function as nodes in an intelligent, enterprise-scale data mesh.
Interoperable Architecture
Interoperability ensures domains interconnect through standardized definitions, shared semantic layers, and master data harmonization, creating a single, consistent version of truth across internal and external sources. Following a medallion architecture, raw data (Bronze) is refined, integrated (Silver) and transformed into business-ready Gold assets, with clear definitions at each layer. Ingestion pipelines handle both structured and unstructured data with appropriate enrichment, validation, and latency management. Data Models and Business Rules define the structural and operational rigor: conceptual models cut across domains, and transformation logic, validation checks, and quality rules ensure accuracy, consistency, and compliance. Metrics & Feature Stores provide trusted measures and KPIs that underpin analytical products and ML use cases. Standards-first design, lineage conventions, and semantic alignment guarantee consistency and accelerate downstream adoption.
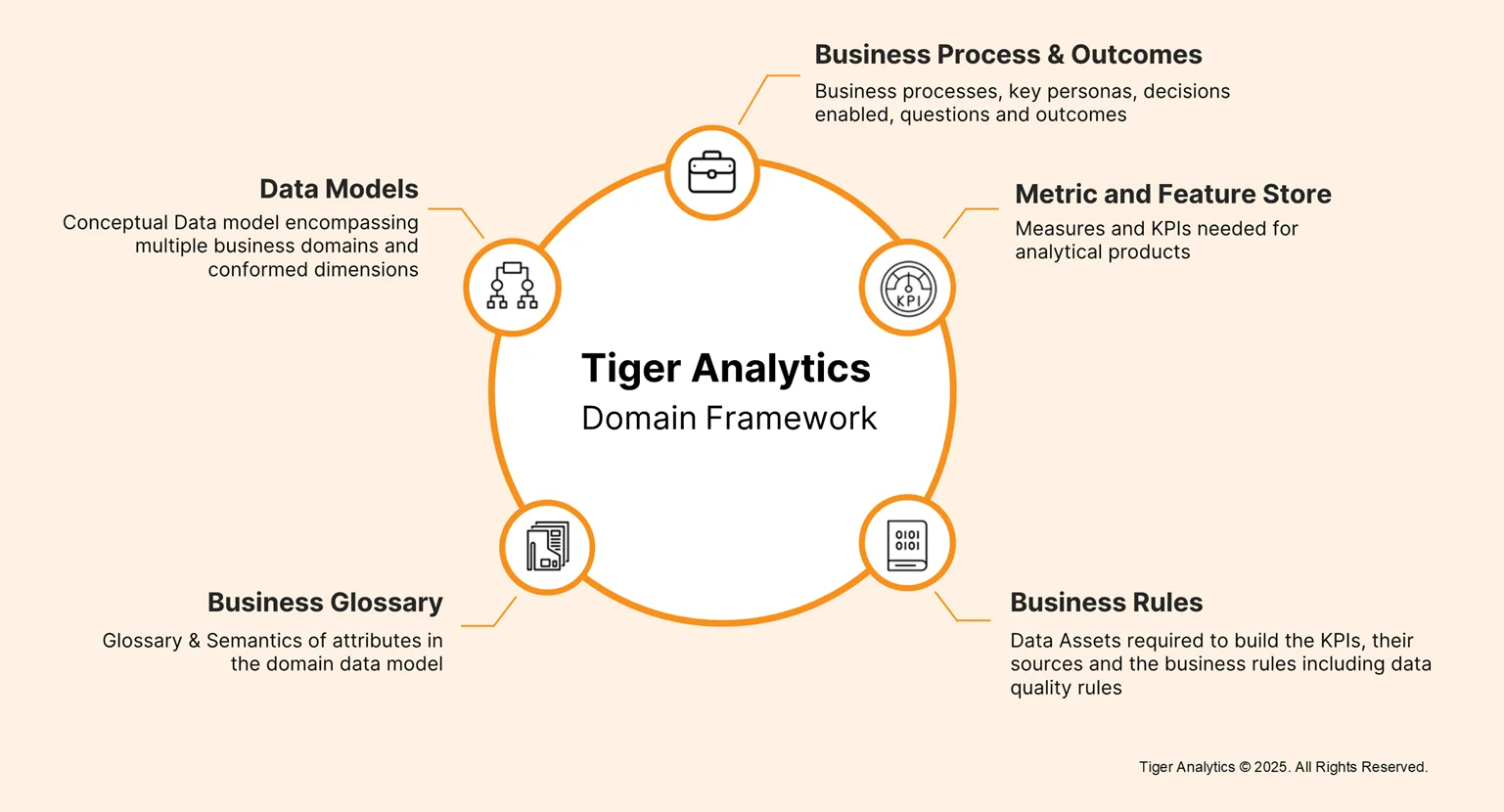
Persona-Based Design
Products that ignore human context risk adoption challenges. This principle maps business personas, sales managers, risk analysts, marketing strategists, to Gold-layer outputs, tying metrics, KPIs, business rules, and lineage to the decisions each persona needs to make. Business Processes & Outcomes and the Business Glossary reside here, contextualizing metrics, providing semantics, and enabling agentic AI to reason about decisions. The result is impact-driven intelligence: data products that answer “so what?” for every user and system consuming them.
Value-Driven Lifecycle
Data products generate measurable business value throughout their lifecycle, from incubation to decommissioning. Agile development prioritizes requests by value, builds MVPs, and iteratively expands features. Cross-functional teams, such as modeling, governance, and engineering, operate in parallel, while agentic AI accelerates metadata enrichment, testing, validation, and semantic reasoning. This ensures technical sophistication translates into faster insights, higher adoption, and cost savings.
By combining domain-oriented ownership, interoperable Silver-to-Gold pipelines, persona-linked metrics, and a value-driven lifecycle accelerated with AI, this framework turns complex enterprise data into consistent, trusted, interpretable, and actionable insights.
Use Case: Trade Promotion Optimization in Revenue Management for CPG
Consider a CPG firm focusing on revenue management within the demand domain. The organization’s data landscape is structured by business-function domains that is HR, Finance, Supply, Demand, and R&D, with master data forming a foundational layer. Within revenue management, trade promotion optimization demonstrates how domain-specific data products serve multiple tiers of analytical needs, from historical performance to predictive planning.
Trade promotion data products address three tiers of analysis:
- Diagnostic insights: Understanding what happened in past promotions, attribution across channels, and customer purchase behavior.
- Descriptive insights: Tracking ongoing promotions, analyzing which products and retailers are performing best in real time.
- Prescriptive and predictive insights: Guiding future decisions, such as optimal allocation of promotional spend, selecting retailers, and predicting product performance.
Key personas, such as account managers and planners, rely on these products to make operational and strategic decisions. They need to understand both the effectiveness of current promotions and forecast future outcomes. Explicitly linking data products to these personas ensures analytics are actionable, adoption is high, and technical sophistication translates into business impact.
The underlying architecture leverages the medallion paradigm:
- Silver layer: Harmonizes and enriches raw transactional and master data.
- Gold layer: Transforms Silver data into business-ready assets.
- Semantic layer: Provides key metrics, aggregates, and contextual definitions to make outputs interpretable and consistent across analytical products.
Historically, operational teams (promo effectiveness) and planning teams (forecasting) often built separate products, leading to inconsistency. By establishing a shared Silver and Gold foundation, the framework ensures:
- Product, customer, channel, and brand data are consistent across all analytical products.
- Sales transactions from internal and external sources are harmonized.
- ML models and AI agents can leverage the same trusted datasets seamlessly.
This case exemplifies the framework’s core design principles: domain-oriented design, persona focus, interoperability, and value-driven lifecycle. By harmonizing data, defining metrics, and connecting outputs to actionable business decisions, trade promotion optimization transforms complex enterprise data into scalable, intelligence-driven workflows.
As organizations move towards intelligence-driven ecosystems, embedding domain knowledge, human context, and interoperable architectures into data product design can transform enterprise data into a scalable, AI-ready, and actionable asset. Looking ahead, organizations that adopt this connected blueprint will not only accelerate insights but also unlock new opportunities for predictive and prescriptive decision-making across industries.




