The lunch rush is a massive, distributed data event in the Quick Service Restaurant (QSR) industry, a live stress test of the entire operating model. Orders stream in from POS systems, kiosks, and delivery platforms across thousands of locations, each one shifting inventory, labor demand, and fulfillment pressure in real time. What looks like routine transactions at first glance, is actually a tightly coupled system reacting every second.
The challenge here is the velocity of decision-making. If a store manager cannot see inventory depletion or sales trends in near-real-time, they cannot optimize operations, prep decisions get locked in too early, replenishment reacts too late. And yet, many global brands are still tethered to legacy batch pipelines and fragmented storage systems.
At Tiger Analytics, we recently partnered with a leading global QSR brand to rethink the transaction backbone as a live, event-driven DataHub. Built on Apache Iceberg and Amazon S3 Tables on AWS, the goal was to make operational data usable while the service window is still unfolding.
Why Legacy QSR Pipelines Fracture
As transaction volumes and operational demands grew, the client’s existing architecture was beginning to evolve beyond the design assumptions it was originally built for. Together, we identified opportunities to strengthen scalability, responsiveness, and operational resilience across the platform:
- Database Contention and Exhaustion: The legacy design executed Transactional Lambdas directly within Step Functions, which at peak transaction spikes placed pressure on ODS connections and occasionally pushed concurrency limits.
- The 180-Second Barrier: Without a strong buffering layer in place, the system found it challenging to consistently meet the 3-minute near-real-time (NRT) processing target during high-throughput windows.
- Small-File Fragmentation: Ingesting 4,000–8,000 micro-files per hour, with an average of 100 transaction records packed into each file, generated a massive “small-file storm” across S3. This continuous streaming of 20 to 30 million records per day accumulated staggering metadata overhead that quickly degraded downstream analytical query speeds.
- Data Integrity Considerations: The absence of automated reconciliation introduced additional complexity in ensuring end-to-end financial accuracy, particularly for transactions processed around the 00:00 UTC boundary.
Building a Two-Track Architecture with AWS, Apache Iceberg, and Event-Driven Design
One of the core architectural decisions was recognizing that operational responsiveness and analytical scale place fundamentally different demands on a data platform. Store-facing dashboards and transaction lookups require low-latency, isolated access patterns, while analytical workloads are designed for large-scale aggregation, historical context, and multi-engine querying.
Rather than forcing both through a single processing path and introducing avoidable contention, we re-architected the pipeline as a resilient, event-driven system that captures global POS data once and fans it out into two purpose-built paths:
1. The Operational Path (ODS)
For real-time store lookups, a dedicated router fans out events into 27 individual SQS queues. Each of the 27 POS message types is processed by its own Lambda and stored in Amazon Aurora. This ensures that operational dashboards remain highly responsive and isolated from heavy analytical workloads.
2. The Analytical Path (Apache Iceberg on AWS)
This is where Apache Iceberg played a key role. Raw events trigger a Lambda-driven transformation before flowing through Amazon Kinesis Firehose directly into Amazon S3 Tables formatted as Apache Iceberg tables.
This shift introduced a set of capabilities that address common limitations with traditional data lakes:
- ACID Transactions: Iceberg ensures zero corruption during concurrent streaming and batch operations.
- Automated Maintenance at Scale: Amazon S3 Tables natively handle automatic background compaction. They continuously merge micro-batches into optimal Parquet files, solving the small-file fragmentation issue without requiring manual maintenance scripts or expensive Glue compaction jobs.
- Multi-Engine Interoperability: Utilizing the S3 Tables Iceberg REST Catalog, the data layer serves as a single source of truth. Query engines like Amazon Athena and external platforms like Snowflake can query the exact same S3 footprint simultaneously without data duplication or manual catalog syncing.
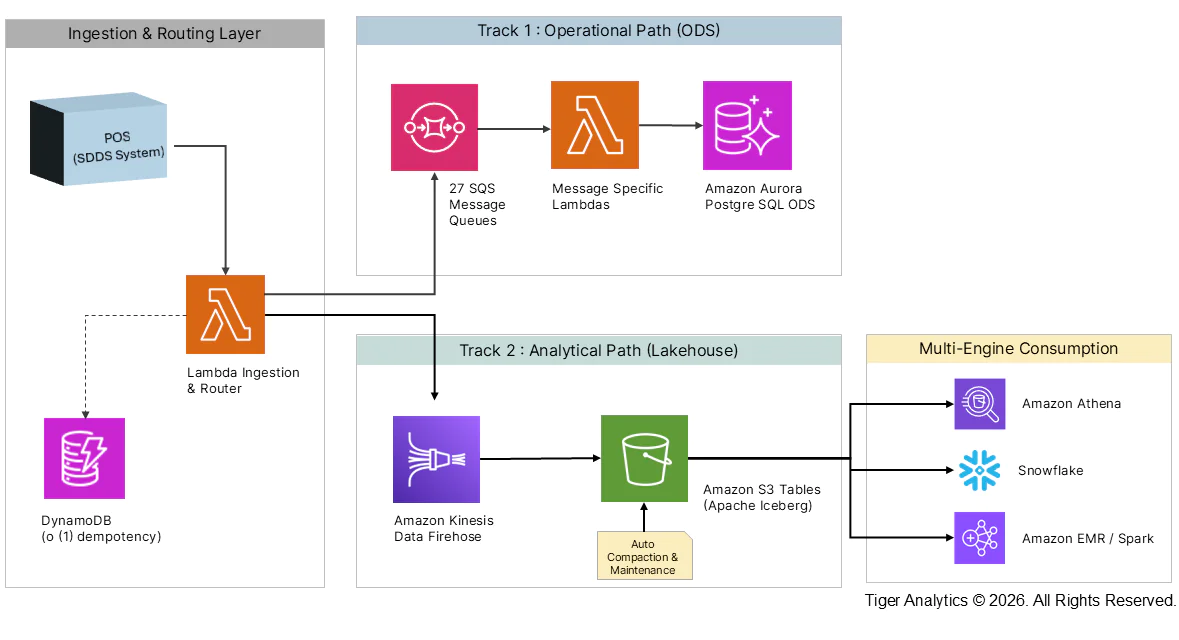
Tiger Analytics Two-Track Event-Driven Architecture showing Operational Path via Amazon Aurora and Analytical Path via Amazon S3 Tables and Apache Iceberg
To ensure this data was ‘system of record’ quality, we also implemented a robust governance framework:
- Multi-Level Idempotency: PostgreSQL audit tables were swapped with DynamoDB. Using $O(1)$ lookups, we could prevent duplicates at the batch, message, and transaction levels.
- Global Data Reconciliation: We developed custom logic to solve midnight drift, which ensured messages processed near 00:00 UTC are accurately reconciled across adjacent days.
- Fault Tolerance: For making sure that the distributed engine is made into a reliable system of record, all transactions passing through the hub are managed under a dual control mechanism based on metadata layer that uses pos_batch_control and pos_message_control. This will make sure that there is a permanent audit trail, allowing us to have partial batch success through PostgreSQL SAVEPOINT where valid store transactions are committed immediately regardless of whether there is an error in any peer transaction in the micro-batch.
- Observability at Scale: A high degree of distribution, serverless architecture, and multi-regional management demands extensive monitoring capability. We leveraged Dynatrace and OpsGenie for full-stack observability, tracking the timeline of executions across several thousand distinct Lambda functions for proactive alerting and incident management, ensuring no bottle-neck impacts our store dashboards.
The Result: Improving Speed, Scale, and Cost Efficiency
The modernization of the POS DataHub helped shift the brand’s data platform from a constrained operational system to a more reliable enterprise asset. The impact observed includes:
- Processing SLA: Achieved end-to-end delivery in under 3 minutes.
- Peak Throughput: The system successfully handles 8,000+ concurrent file executions per hour.
- 99.95% Data Integrity: The custom automated reconciliation engine guarantees financial-grade accuracy between the operational and analytical layers.
- 70% Storage Cost Reduction: By decoupling compute from storage and moving long-term history out of traditional data warehouses into S3 Tables, storage costs were reduced by approximately 70%.
Overall, separating storage from compute and introducing a table format layer helped reduce earlier trade-offs between scale and responsiveness. More broadly, it reflects a pattern seen in many large-scale data environments: once fragmentation and tight coupling are addressed, performance and cost efficiency tend to improve together.
Orchestrating the Future of QSR Intelligence
Over several engagements, we’ve observed that the modernization of the POS DataHub with platforms like Apache Iceberg reflects a broader shift in how enterprise data platforms are being designed for continuous, high-frequency decisioning. When challenges around scale, concurrency, and near-real-time visibility are addressed at the foundation layer, the conversation moves from making data work to making data continuously usable.
The unified Apache Iceberg-based layer we built with the QSR brand acts as a consistent foundation for several downstream capabilities, including:
- Hyper-Personalized Loyalty Programs: Leveraging years of unified transaction history to drive individual customer engagement.
- Dynamic Supply Chain Optimization: Using real-time item depletion data to automate replenishment and reduce waste across global footprints.
- Predictive Labor Scheduling: Correlating live sales spikes with historical trends to optimize staffing levels in real-time.
- Advanced Fraud Mitigation: Moving beyond simple audits to proactive, AI-driven anomaly detection that identifies suspicious patterns as they happen.
What’s emerging across QSR and similar high-volume industries is a need for faster pipelines and architectures that allow operational and analytical loops to converge. As transaction volumes continue to grow and decisions move closer to the point of action, the differentiator is shifting toward how quickly and reliably data can be turned into something operational systems can act on. In that context, modern data lake architectures are becoming more about enabling a continuous feedback loop between what is happening and what should happen next.




