Historically, manufacturing equipment maintenance has been done during scheduled service downtime. This involves periodically stopping production for carrying out routine inspections, maintenance, and repairs. Unexpected equipment breakdowns disrupt the production schedule; require expensive part replacements, and delay the resumption of operations due to long procurement lead times.
Sensors that measure and record operational parameters (temperature, pressure, vibration, RPM, etc.) have been affixed on machinery at manufacturing plants for several years. Traditionally, the data generated by these sensors was compiled, cleaned, and analyzed manually to determine failure rates and create maintenance schedules. But every equipment downtime for maintenance, whether planned or unplanned, is a source of lost revenue and increased cost. The manual process was time-consuming, tedious, and hard to handle as the volume of data rose.
The ability to predict the likelihood of a breakdown can help manufacturers take pre-emptive action to minimize downtime, keep production on track, and control maintenance spending. Recognizing this, companies are increasingly building both reactive and predicted computer-based models based on sensor data. The challenge these models face is the lack of a standard framework for creating and selecting the right one. Model effectiveness largely depends on the skill of the data scientist. Each model must be built separately; model selection is constrained by time and resources, and models must be updated regularly with fresh data to sustain their predictive value.
As more equipment types come under the analytical ambit, this approach becomes prohibitively expensive. Further, the sensor data is not always leveraged to its full potential to detect anomalies or provide early warnings about impending breakdowns.
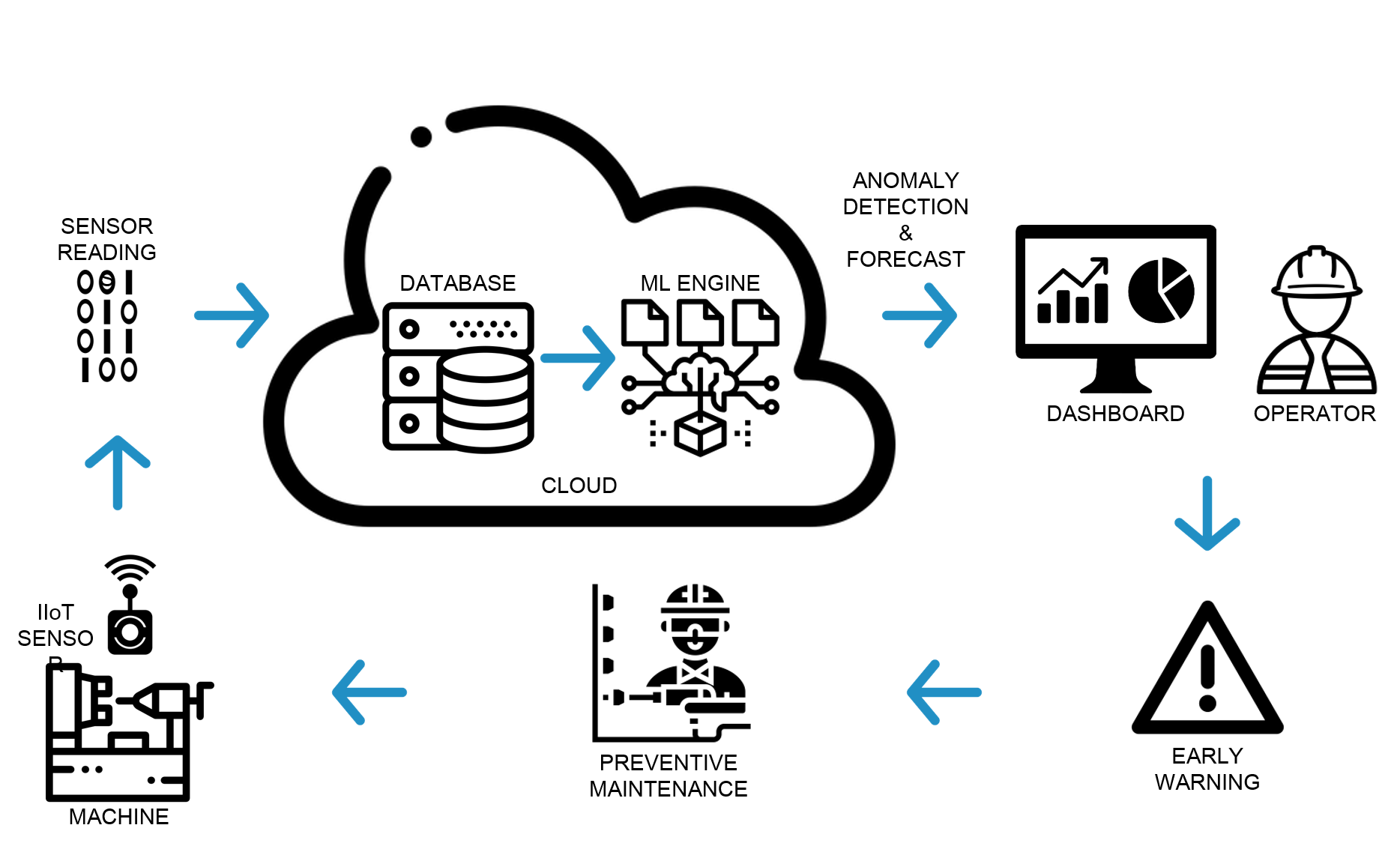
In the last decade, the Industrial Internet of Things (IIoT) has revolutionized predictive maintenance. Sensors record operational data in real-time and transmit it to a cloud database. This dataset feeds a digital twin, a computer-generated model that mirrors the physical operation of each machine. The concept of the digital twin has enabled manufacturing companies not only to plan maintenance but to get early warnings of the likelihood of a breakdown, pinpoint the cause, and run scenario analyses in which operational parameters can be varied at will to understand their impact on equipment performance.
Several eminent ‘brand’ products exist to create these digital twins, but the software is often challenging to customize, cannot always accommodate the specific needs of each and every manufacturing environment, and significantly increases the total cost of ownership.
ML-powered digital twins can address these issues when they are purpose-built to suit each company’s specific situation. They are affordable, scalable, self-sustaining, and, with the right user interface, are extremely useful in telling machine operators the exact condition of the equipment under their care. Before embarking on the journey of leveraging ML-powered digital twins, certain critical steps must be taken:
1. Creation of an inventory of the available equipment, associated sensors and data.
2. Analysis of the inventory in consultation with plant operations teams to identify the gaps. Typical issues may include missing or insufficient data from the sensors; machinery that lacks sensors; and sensors that do not correctly or regularly send data to the database.
3. Coordination between the manufacturing operations and analytics/technology teams to address some gaps: installing sensors if lacking (‘sensorization’); ensuring that sensor readings can be and are being sent to the cloud database; and developing contingency approaches for situations in which no data is generated (e.g., equipment idle time).
4. A second readiness assessment, followed by a data quality assessment, must be performed to ensure that a strong foundation of data exists for solution development.
This creates the basis for a cloud-based, ML-powered digital twin solution for predictive maintenance. To deliver the most value, such a solution should:
- Use sensor data in combination with other data as necessary
- Perform root cause analyses of past breakdowns to inform predictions and risk assessments
- Alert operators of operational anomalies
- Provide early warnings of impending failures
- Generate forecasts of the likely operational situation
- Be demonstrably effective to encourage its adoption and extensive utilization
- Be simple for operators to use, navigate and understand
- Be flexible to fit the specific needs of the machines being managed
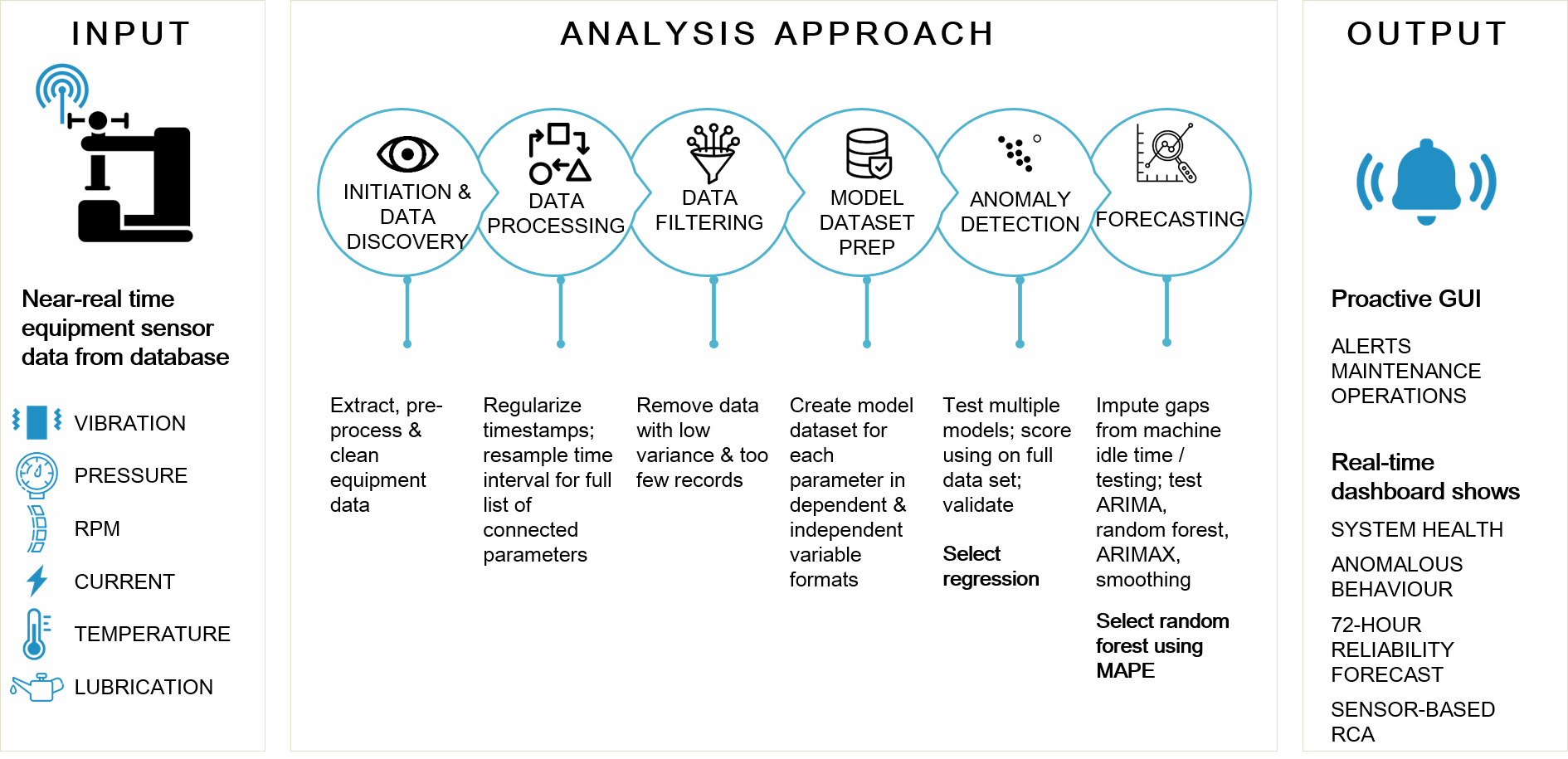
When model-building begins, the first step is to account for the input data frequency. As sensors take readings at short intervals, timestamps must be regularized and resamples taken for all connected parameters where required. At this time, data with very low variance or too few observations may be excised. Model data sets containing sensor readings (the predictors) and event data such as failures and stoppages (the outcomes) are then created for each machine using both dependent and independent variable formats.
To select the right model for anomaly detection, multiple models are tested and scored on the full data set and validated against history. To generate a short-term forecast, gaps related to machine testing or idle time must be accounted for, and a range of models evaluated to determine which one performs best.
Tiger Analytics used a similar approach when building these predictive maintenance systems for an Indian multinational steel manufacturer. Here, we found that regression was the best approach to flag anomalies. For forecasting, the accuracy of Random Forest models was higher compared to ARIMA, ARIMAX, and exponential smoothing.
Using a modular paradigm to build ML-powered digital twin makes it straightforward to implement and deploy. It does not require frequent manual recalibration to be self-sustaining, and it is scalable so it can be implemented across a wide range of equipment with minimal additional effort and time.
Careful execution of the preparatory actions is as important as strong model-building to the success of this approach and its long-term viability. To address the challenge of low-cost, high-efficiency predictive maintenance in the manufacturing sector, employ this sustainable solution: a combination of technology, business intelligence, data science, user-centric design, and the operational expertise of the manufacturing employees.
This article was first published in Analytics India Magazine.




