How can organizations cut through the Generative AI hype to plan, build, and launch a Gen AI plan that actually works for their unique needs?
The science behind it evolved steadily over time. Supporting computational architectures grew manifold in the Cloud + GPU/TPU era. The phrase itself started showing up a bit nondescript in AI hype cycles from 2020 onwards, with a predicted timeline of 2-5 years from peak to plateau.
Against all this backdrop and thanks to ChatGPT, in late 2022, ‘Generative AI’ (GenAI) resurfaced on the scene with a big bang, creating an all-around buzz from discussion boards to boardrooms.
For organizations looking to leverage Gen AI technologies as a part of their Analytics strategy, certain action areas with a need for clear ownership stand out as important: creating the right excitement, adopting a sustainable technical approach (vs. not-for-all trillion token adventures), and having a method to generate value safely at scale.
These are applicable for Gen AI-based solutions as much as for Data and AI in general, but with some nuances. We believe organizations can tap into the following windows of opportunity while planning on how to integrate Gen AI into their business.

How can organizations tap into these windows of opportunity to create tangible value for their businesses? Here’s a simple three-step process:
Step 1: Plan: Creating your own Gen AI strategy
With different departments at varying levels of data maturity, the first step would be to determine which projects and departments are best suited for Gen AI integration.
A time-tested approach could help:
- Through Design Thinking-styled workshops with stakeholders across functions (or one key function at a time), organizations could generate an exhaustive list of candidates from the ground up without placing any constraints upfront.
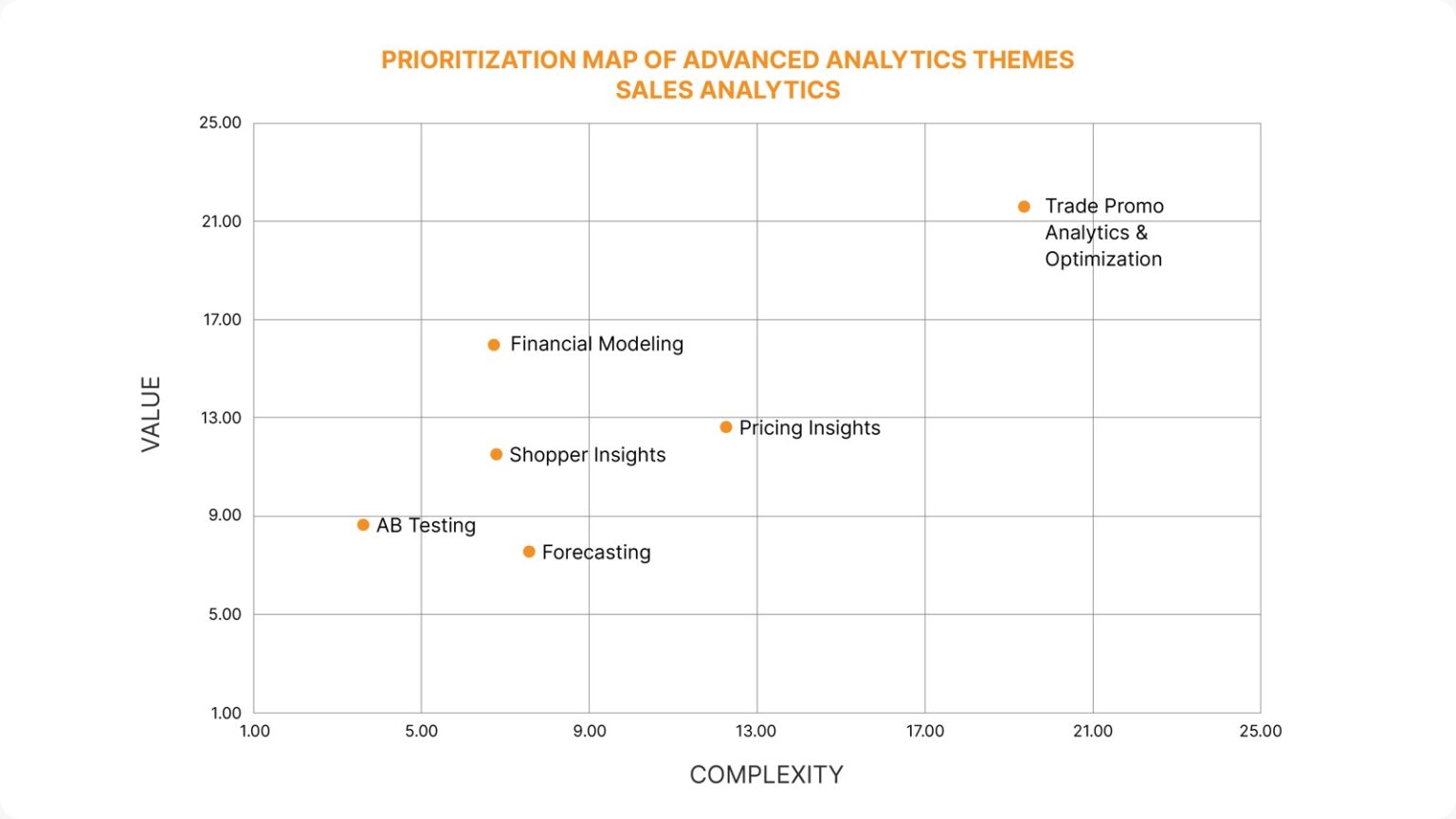
- All candidate ideas could be plotted on a Value vs. Complexity matrix.
- Use cases could then be prioritized objectively, with debates where needed, and top candidates picked for a pilot.
Coming out of such ideation workshops, here are some key questions that should have been answered:
- What is the high-level business opportunity and/or estimated value the use case can generate?
- Is Gen AI the right solution for the problem/ Is Gen AI required to solve it?
- What are the success criteria for the use case?
- How complex is the implementation?
- Is the required data available to develop the solution?
- Do the required tools, technology, processes, and people skills/capabilities exist in the organization?
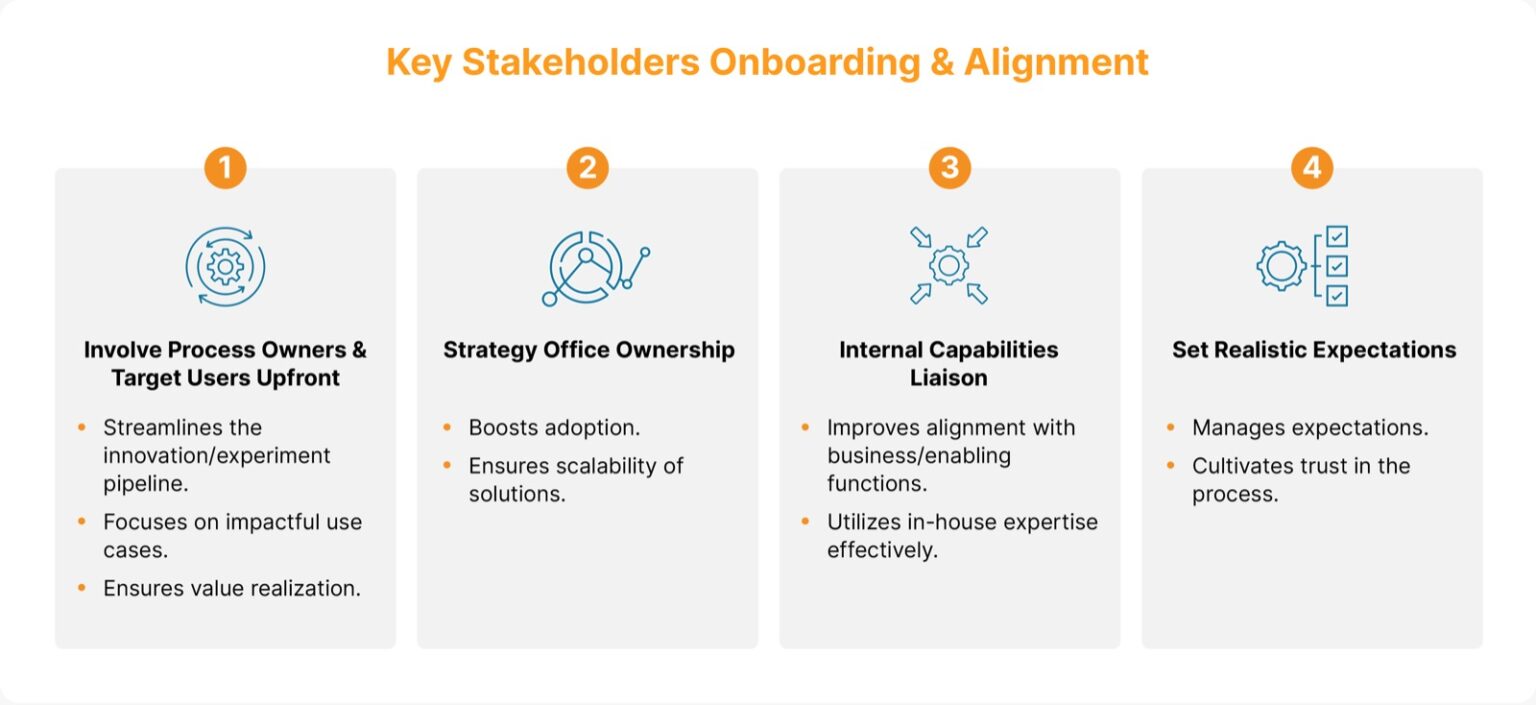
It is also essential to have key stakeholders onboard and aligned. We see different strategies being adopted to ensure that happens.
- Upfront involvement of process owners and target users ensures solution relevance, as well as down-the-line adoption and scaling. This also avoids the risk of clogging a very busy innovation/experiment pipeline (blame it on the buzz) with lukewarm use cases, which may not see adoption and hence experience lesser value.
- Having the Strategy Office own and drive business use case identification also helps with adoption and scalability.
- Look for internal capabilities (bandwidth and skills of the existing Data and Analytics function) to liaise with business/enabling functions.
- Set realistic expectations with participants about time-to-impact at full scale, given the space is still nascent, albeit with significant potential.
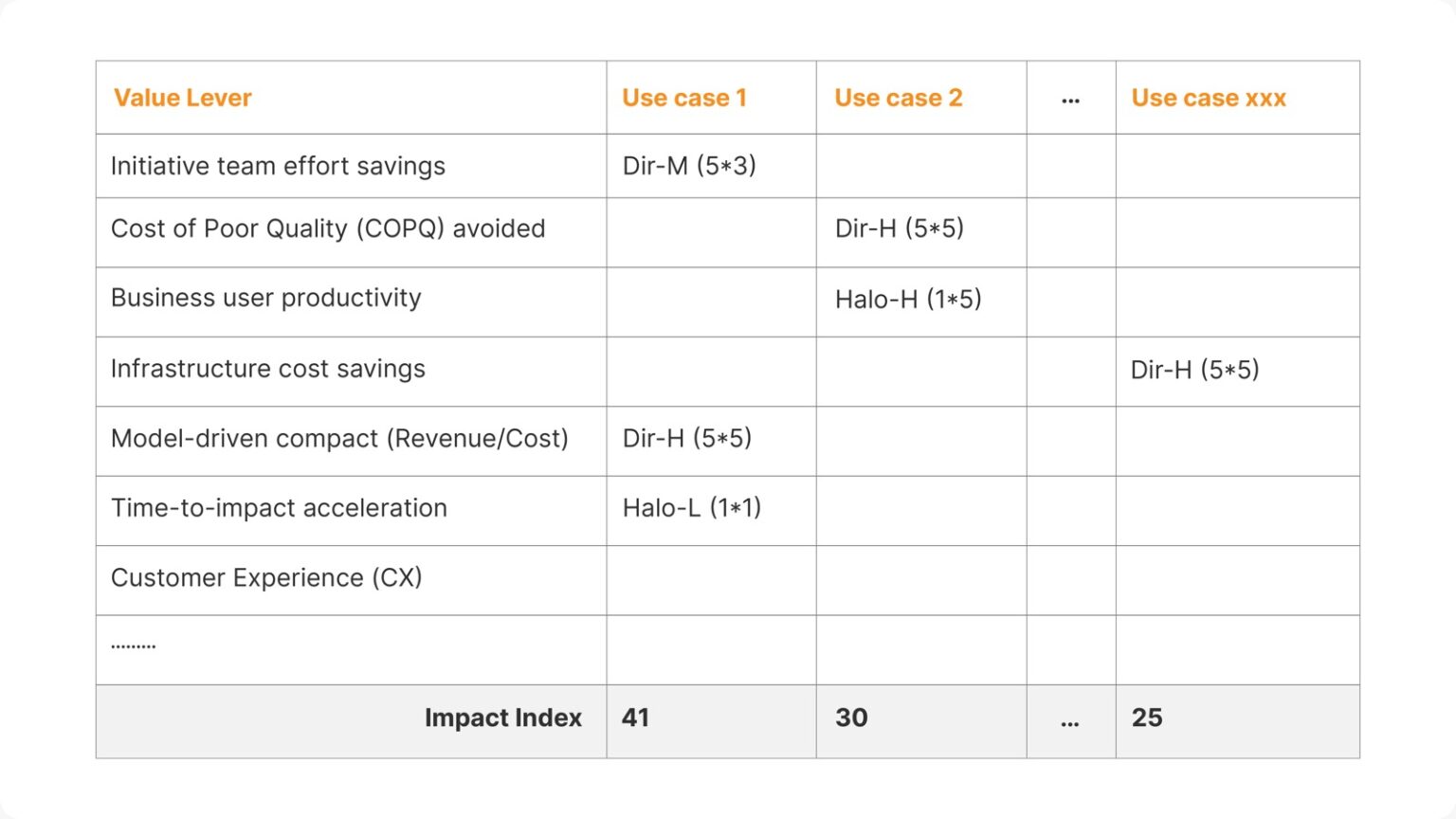
Assessing the potential value and risks of candidates could consider direct and halo impact across multiple dimensions such as
- Effort savings in the immediate team (say Data and AI team)
- Business user productivity impact
- Impact to end customer
- Cost of poor (data) quality avoidance
- Infrastructure/platform cost savings
- Potential impact (revenue) of model-driven decisions
- Time to impact acceleration and increase in adoption (scale)
An illustrative view of high-level direct and halo impact-based ranking of ideas is shown here. After arriving at a shorter list of use cases, you can create a more detailed calculation with assumptions.
Step 2: Build: Choosing a solution architecture that works best for you
Once you’ve identified the gaps and growth opportunities that you need Gen AI to address within your business, it’s important to explore the solution architecture that best suits your requirements.
Training up a foundation model from the ground up may not be needed in many cases. However, the choices you make would in turn have a significant influence on the objective and qualitative performance measures of these solutions, along with the upfront and ongoing costs.
Some of the questions that are relevant and influenced by the breadth of business cases that need to be addressed are:
- Would it suffice to just transact with an enterprise model API?
- Would fine-tuning and prompting of open-source models work better?
- If yes, what sources, how much, and what’s the prep work needed for data quality?
- How to set up continuous tuning?
- When to hit the enterprise model API and when to pick from archived prompts/completions?
- Which model, platform, and cloud infrastructure should you opt for?
- How to prepare for and address the different risks that may crop up during each stage of implementation?
Picking up shortlisted business use cases (from the Plan phase), engaging the right technical leadership from within the organization, and seeking assistance from experienced AI-based solution providers where needed will help decide the right technical architecture upfront, avoid throwaways, or worse, costly lock-ins.
Across different sources, client conversations along with the many aspects of training Gen AI models using the organization’s data, a pattern of utility emerges:
- Enterprise Model APIs: Leveraged for Search and Summarization tasks on documents without risk(s) of confidentiality breach (For example: Handling product-related queries from customers on publicly available product manuals)
- Custom LLMs: Models built through fine-tuning of open-source models and smart prompting. Depending on the extent of fine-tuning data, and additional embedding with prompting efforts, the utility of this class of models ranges from quickfire proof of capability to the CPG example mentioned earlier (GenAI based autonomous agents to address a broad range of queries from business personas – brand and key account leadership)
- Ensemble of Open-Source Models/LLMs: This constitutes multiple models used as such without tuning but arranged in an ensemble by spending significant engineering effort to handle a broad range of tasks.
- New foundation models: Relevant in scenarios, where the organization is faced with extremely specialized problems with high stakes of getting right/wrong [possibly, large-scale human health solutions, involving data from public research mixed with proprietary R&D content in text and imagery].
Most business experiments at this point though, are in categories #1 and #2. Building custom models is an area of tremendous interest for a whole host of reasons, including litigation risk on some of the enterprise models behind APIs.
At Tiger Analytics, we evaluate various possible approaches, shown below, based on our clients’ use cases and needs:
- Prompt Engineering using Enterprise-grade Generative Models – For example: Chain of thought, zero-shot examples, few-shot examples
- Prompt tuning using any of the open-source LLM models – For example: Prompt tuning, Prefix tuning, and PEFT
- Fine-tuning an open-source LLM model for a specific task – For example: Causal Language Modeling (CLM) and Masked Language Modeling (MLM) on objectives like summarization, code generation, etc.
- Building a foundational LLM model with multiple tasks capability using RLHF loop.
Step 3: Deliver: From conversations to results
After integrating Gen AI interventions into your overall data strategy and ensuring that your solution architecture is the right fit for your use case, you’ll need to factor in a few things to make sure that the Gen AI project implementation is robust, secure, and scalable.
Like all tech adoption programs, ensure that your Gen AI strategy is aligned with your business needs. Here are a few pillars to ensure a successful and seamless project implementation:
The delivery pillars for a successful Gen AI project implementation
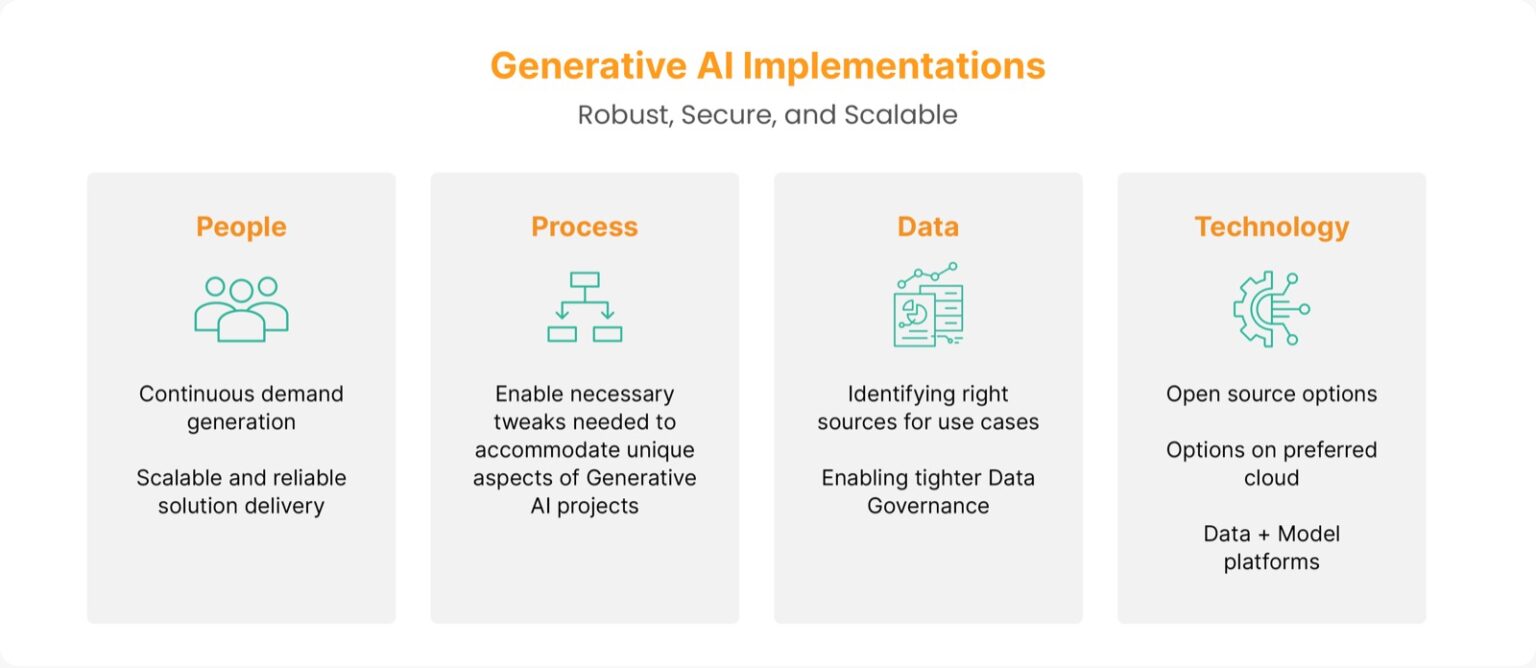
People:
Having the right mix of skills in a team, possibly a Gen AI task force carved out from within the existing Data and Analytics function, collaborating with specific points of contact identified from participating functions and with the strategy office to ensure:
- Continuous Demand Generation: A pipeline of business use cases, identified and prioritized for execution from across the enterprise
- Solution Delivery: Comprising of relevant technical talent, the right architecture, outcome with the desired features and optimal experience, and more importantly, housekeeping to evolve a cohesive Gen AI model asset pool
Initiating delivery governance, evangelizing initial success stories to drive adoption at scale, and keeping a tab on potential risks, all need to be handled through appropriate leadership structure and accountability.
Process:
Whether it is for business engagement, human-centric design, product management, model asset management, agile and DevOps processes for technical deliverables, value measurement, and articulation, many processes and frameworks already exist within companies. Minor tweaks needed to accommodate unique aspects of GenAI projects should be sufficient. Data management processes, though, would significantly evolve, as outlined in the next section.
Data:
Data from well-structured document stores (for example: presentations and contract databases), MarTech digital asset management platforms, semi-structured sources such as emails and attachments, chat systems, and other collaboration ware could be helpful in developing cognitive models of how business processes are executed and special situations handled. Keeping an eye out for such sources, alongside business use case identification, should help magnify impact.
A key aspect of data management is enabling tighter governance. Evaluating and addressing the following questions could help ensure robust data management:
- What goes into training/tuning models?
- What comes out for immediate action, storage, and subsequent reuse?
- Are we maintaining an audit trail of these for current/evolving regulatory requirements?
Technology (models and beyond)
While technology – cloud ware, GPU/TPUs, new models, integrated Data and AI platforms – are all evolving very rapidly, some key options stand out.
- Open source options: Depending on the business use case, and the organization’s capability/appetite to custom build solutions, carefully picked open source models could enable significant scalability.
- Options on the preferred cloud: With a range of ready-to-use enterprise model APIs, take and tweak open source models, and associated cost structures, options such as Azure OpenAI models could significantly accelerate the GenAI journey by handling a lot of additional activities required to deliver safe, scalable solutions.
- Data + Model platforms: Databricks announcing its intent to acquire MosaicML is an example of an even more nuanced offering – an integrated platform to manage data + model assets (lakehouse with mosaic floor), and the ability to do this in different cloud environments. More options of this kind could open up in the near future.
The key point to note, however, is that there is no clear pick-this-over-that prescription anyone could recommend, sitting far outside an organization’s context. Investing quality time of a multi-functional team that has deep context to perform the necessary due diligence and define a sustainable roadmap is the only recipe for long-term value creation. It is also the reason why the order is People, Process, Data, and Technology.
Time to generate results
Many of us are fortunate to be in a space that’s operating at the frontiers of human knowledge. This offers opportunities to learn new things and apply them along the way, creating a positive impact on the stakeholders we touch – within and outside our organizations and to ourselves as individuals.
While the Gen AI wave continues to reimagine the way we work and live, we’ve only begun to tap its true disruptive potential. Will businesses be able to successfully ride the Gen AI hype train to their destination of choice? How smoothly will they transition from conversations to adoptions? That’s something only time can tell.
This article was published in the Analytics India Magazine.