Effectively enabling SAP data analytics on Azure Databricks empowers organizations with a powerful and scalable platform that seamlessly integrates with their existing SAP systems. They can efficiently process and analyze vast amounts of data, enabling faster insights and data-driven decision-making.
So, if you’re a senior technical decision-maker in your organization, choosing the proper strategy to consume and process SAP data with Azure Databricks is critical.
First, let’s explore the types of SAP data and objects from the source system. Then, let’s see how the SAP BW can be accessed and made available to Azure Databricks for further processing, analytics, and storing in a Databricks Lakehouse.
Why Enable SAP Data Analytics on Azure Databricks
While SAP provides its data warehouse (SAP BW), it can still add value to extract operational SAP data from the SAP sources (S4/Hana or ECC) or SAP BW into an Azure Databricks Lakehouse – integrating it with other ingested data, which may not originate from SAP.
As a practical example, let’s consider a large and globally operating manufacturer that utilizes SAP for its production planning and supply chain management. It must integrate IoT machinery telemetry data stored outside the SAP system with supply chain data in SAP. This is a common use case, and we will show how to design a data integration solution for these challenges.
We will start with a more common pattern to access and ingest SAP BW data into the Lakehouse by using Azure Databricks and Azure Data Factory/ Axure Synapse Pipelines.
This first part will also lay important foundations to better illustrate the material presented. For example, imagine a company like a manufacturer mentioned earlier currently operating an SAP System on-premises with an SAP BW system. This company needs to copy some of its SAP BW objects to a Databricks Lakehouse in an Azure ADLS Gen 2 account and use Databricks to process, model, and analyze it.
There will likely be many questions for the scenario mentioned with the import from SAP BW, but the main questions we would like to focus on are:
- How should we copy this data from the SAP BW to the Lakehouse?
- What services and connectivity are going to be required?
- What connector options are available to us?
- Can we use a reusable pattern that is easy to implement for similar needs?
The reality is that not every company has the same goals, needs, and skillsets, so there isn’t one solution that fits all needs and customers.
SAP Data Connection and Extraction: What to Consider
We can connect and extract many ways, tools, and approaches, respectively, pull and push SAP Data from its different layers (Database tables, ABAB Layer, CDS Views, IDOCS, etc.) into the Databricks Lakehouse. For instance, we can use SAP tooling such as SAP SLT or other SAP tooling or another third-party tooling.
It makes sense for customers already in Azure to use the different sets of connectors provided in Azure Data Factory/ Azure Synapse to connect from Azure to the respective SAP BW instance running on-premises or in some other data center.
Depending on the different ways and tools of connecting, SAP licensing also plays an important role and needs to be considered. Also, we highly recommend an incremental stage and load approach, especially for large tables or tables with many updates.
It may be obvious, but in our experience, each organization has a unique set of needs and requirements when it comes to accessing SAP Data, and an approach that works for one organization may not be a good fit for another given its needs, requirements, and available skills. Some important factors to ensure smooth operations are licensing, table size, acceptable ingestion latency, expected operational cost, express route throughput, and size and number of nodes of the integrated runtime.
Let us look at the available connectors in ADF/ Synapse and when to use each.
How to Use the Right SAP Connector for Databricks and ADF/ Synapse

As of May 2023, ADF & Synapse currently provides seven different types of connectors for SAP-type sources. The image below shows all of them filtered by the term “SAP” in the linked services dialog in the pipeline designer.
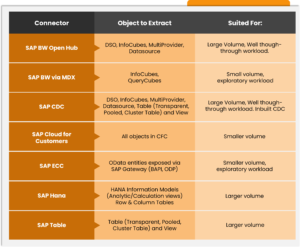
Now, we would like to extract from SAP BW. We can use options 1, 2, 3, and 7 for that task. As mentioned earlier, for larger tables or tables with many updates, we recommend options 1, 7, or option 3. The SAP CDC connector (Option 3) is still in public preview, and we recommend not using it in production until it is labeled “generally available.” However, the SAP CDC connector can be utilized in lower environments (Dev, QA, etc.). Option 2 will not be fast enough and likely take too much time to move the data.
There’s certainly more to be understood about these ADF connectors and approaches of directly connecting Azure Databricks to relevant SAP sources and data push approaches initiated by SAP tooling such as SAP SLT. But, for now, the pattern introduced in Azure using connectors in ADF and Synapse is very common and reliable.
SAP ODP: What You Should Know
So far, only the SAP CDC connector from above is fully integrated with SAP ODP (Operational Data Provisioning). As of May 2023, we may still use other connectors, given that all other connectors are stable and have been in production already for years. However, it is recommended to slowly plan for more use of ODP connectors, especially when it is a green field development. The project is about to start within the next month or so. So let us look closely at SAP ODP and its place in the process.
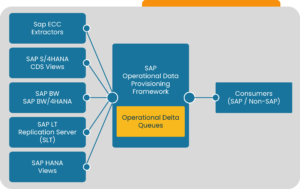
As shown in Image 2, SAP ODP-based connector is like a broker between the different SAP data providers and the SAP Data Consumers. An SAP Data Consumer like ADF, for instance, does not directly connect to an SAP data provider once connected via SAP ODP connector. Instead, it connects to the SAP ODP Service and sends a request to provide data to the service. The service then connects to the respective data provider to serve the requested data to the data consumer.
Depending on the configuration of the connection and the respective data provider, data will be served as an incremental or full load and stored in ODP internal queues until a consumer like ADF can fetch it from the queues and write it back out to the Databricks Lakehouse.
SAP ODP-based connectors are the newer approach to accessing SAP data, and as of May 2023, the SAP ODP-based CDC connector is in public preview. SAP ODP isn’t new within the SAP world and has been used internally by SAP for data migration for many years.
One major advantage is that the SAP ODP CDC connector provides a delta mechanism built into ODP, and developers no longer have to maintain their watermarking logic when using this connector. But, given that it isn’t yet generally available, it should be applied with care and, at this stage, possibly just planned for.
Obviously, we also recommend testing the watermarking mechanism to ensure it fits your specific scenarios.
How to Put It All Together with Azure Databricks
Now, we are ready to connect all the parts and initially land the data into a landing zone within the Lakehouse. This process is shown in Image 3 below. But, before that step, we ingested the SAP operational data from its applications and backend databases (HANA DB, SQL Server, or Oracle Server) to SAP BW.
Later, we will also look at these SAP BW ingestion jobs and how to migrate their logic to Azure Databricks to be able to refactor them and apply these transformations on top of the source tables imported from SAP ECC or S4/ Hana to the Databricks Lakehouse.
We need to set up an Integrate Runtime for ADF to connect to SAP BW via the SAP BW Open Hub. ADF requires this service to connect to SAP BW. We also need to install the proper SAP BW drivers on the SAP BW server. Typically, in a production environment, the Integrated Runtime is installed on separate machines – hosted in Azure or on-premises and uses at least two nodes for higher levels of availability.
Up to four nodes are possible in a cluster, which is an important consideration for large table loads to set up like that to account for any performance SLAs.
Multiple integrated runtimes will be required for organizations with very large SAP deployments and SAP data ingestion needs. We highly recommend careful capacity and workload planning to ensure the clusters are properly sized and the type of connectivity between Azure and on-premises is sufficient, assuming SAP BW runs on-premises.
From the landing zone, which is just a copy of the original data with typically some batch ID added to the flow, we can utilize the power of the Databricks Delta Lake and Databricks Notebooks containing the code with many language options available (Spark SQL, Python, Scala are the most common choices) to process further and “model” the data from the landing zone into the respective next zones bronze, silver and finally into the gold layer.
Please note this is a slightly simplified view. Typically, the Data Ingestion is part of an overall Data Processing Framework that provides metadata information on tables and sources to be ingested and the type of ingestion desired, such as full or incremental, just as an example. These implementation details aren’t in scope here, but please remember them.
For secure deployment in Azure, every Azure Service part of the solution should be configured to use private endpoints, and no traffic would ever traverse the public Internet. All the services must be correctly configured since this private endpoint configuration is not the default setup with PaaS Services in Azure.
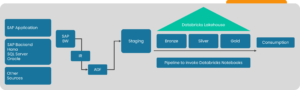
We recommend integrating data test steps typically executed before the data lands in the gold layer. Tiger’s Data Processing Framework (Tiger Data Fabric) provides a semi-automated process to utilize AI capabilities from Databricks to mature data quality through interaction with a data subject matter expert.
Typically, the Databricks Lakehouse has a clearly defined folder structure within the different layers, and plenty of documentation is available on how to do so. But at a higher level, the bronze and silver layer is typically organized by source systems or areas in contrast to the gold layer, which is typically organized towards consumption aspects and models the data by expected downstream consumption needs.
Why Use Azure Databricks
1. Smooth integration of SAP data with data originating from other sources.
2. Databricks’ complete arsenal of advanced ML algorithms and strong data processing capabilities compared to the limited availability of advanced analytics in SAP BW.
3. Highly customizable data processing pipelines – easier to enrich the data from bronze and silver to the gold layer in the Lakehouse.
4. Significantly lower total cost of ownership.
5. Easy-to-scale for large data volume processing.
6. Industry-standard and mature for large-scale batch and low-latency event processing.
Undoubtedly, effectively leveraging Azure Databricks ensures that organizations can harness the power of SAP data analytics. We hope this article provided some insights on how you can enable SAP data analytics on Azure Databricks and integrate it with your SAP systems.
After all, this integration can empower your organization to work with a robust and scalable platform that allows for efficient processing and analysis of large data volumes.





