Data Science applications are gaining significant traction in the preventive and predictive maintenance of process systems across industries. A clear mindset shift has made it possible to steer maintenance from using a ‘reactive’ (using a run-to-failure approach) to one that is proactive and preventive in nature.
Planned or scheduled maintenance uses data and experiential knowledge to determine the periodicity of servicing required to maintain the plant components’ good health. These are typically driven by plant maintenance teams or OEMs through maintenance rosters and AMCs. Unplanned maintenance, on the other hand, occurs at random, impacts downtime/production, safety, inventory, customer sentiment besides adding to the cost of maintenance (including labor and material).
Interestingly, statistics reveal that almost 50% of the scheduled maintenance projects are unnecessary and almost a third of them are improperly carried out. Poor maintenance strategies are known to cost organizations as much as 20% of their production capacity – shaving off the benefits that a move from reactive to preventive maintenance approach would provide. Despite years of expertise available in managing maintenance activities, unplanned downtime impacts almost 82% of businesses at least once every three years. Given the significant impact on production capacity, aggregated annual downtime costs for the manufacturing sector are upwards of $50 billion (WSJ) with average hourly costs of unplanned maintenance in the range of $250K.
It is against this backdrop that data-driven solutions need to be developed and deployed. Can Data Science solutions bring about significant improvement of the maintenance domain and prevent any or all of the above costs? Are the solutions scalable? Do they provide an understanding of what went wrong? Can they provide insights into alternative and improved ways to manage planned maintenance activities? Does Data Science help reduce all types of unplanned events or just a select few? These are questions that manufacturers need to be answered and it is for the experts from both maintenance and data science domains to address.
Industry understanding of managing planned maintenance is fairly mature. The highlight of this article is therefore focused on unplanned maintenance, which demands a differentiated approach to build insight and understanding around the process and subsystems.
Data Science solutions are accelerating the industry’s move towards ‘on-demand’ maintenance wherein interventions are made only if and when required. Rather than follow a fixed maintenance schedule, data science tools can now aid plants to increase run lengths between maintenance cycles in addition to improving plant safety and reliability. Besides the direct benefits that result in reduced unplanned downtime and cost of maintenance, operating equipment at higher levels of efficiency improves the overall economics of operation.
The success of this approach was demonstrated in refinery CDU preheat trains that use soft sensing triggers to decide when to process ‘clean crude’ (to mitigate the fouling impact) or schedule maintenance of fouled exchangers. Other successes were in the deployment of plant-wide maintenance of control valves, multiple-effect evaporators in plugging service, compressors in petrochemical service, and a geo-wide network of HVAC systems.
Instead of using a fixed roster for maintenance of PID control valves, plants can now detect and diagnose control valves that are malfunctioning. Additionally, in combination with domain and operations information, it can be used to suggest prescriptive actions such as auto-tuning of the valves, which improve maintenance and operations metrics.
Reducing unplanned, unavoidable events
It is important to bear in mind that not all unplanned events are avoidable. The inability to avoid events could be either because they are not detectable enough or because they are not actionable. The latter could occur either because the response time available is too low or because the knowledge to revert a system to its normal state does not exist. A large number of unplanned events however are avoidable, and the use of data science tools improves their detection and prevention with greater accuracy.
The focus of the experts working in this domain is to reduce unplanned events and transition events from unavoidable to avoidable. Using advanced tools for detection, diagnosis, and enabling timely actions to be taken, companies have managed to reduce their downtime costs significantly. The diversity of solutions that are available in the maintenance area covers both plant and process subsystems.
Some of the data science techniques deployed in the maintenance domain are briefly described below:
Condition Monitoring
This has been used to monitor and analyze process systems over time, and predict the occurrence of an anomaly. These events or anomalies could have short or long propagation times such as the ones seen in the fouling in exchangers or in the cavitation in pumps. The spectrum of solutions in this area includes real-time/offline modes of analysis, edge/IoT devices and open/closed loop prescriptions, and more. In some cases, monitoring also involves the use of soft sensors to detect fouling, surface roughness, or hardness – these parameters cannot be measured directly using a sensor and therefore, need surrogate measuring techniques.
Perhaps one of the most unique challenges working in the manufacturing domain is in the use of data reconciliation. Sensor data tend to be spurious and prone to operational fluctuations, drift, biases, and other errors. Using raw sensor information is unlikely to satisfy the material and energy balance for process units. Data reconciliation uses a first-principles understanding of the process systems and assigns a ‘true value’ to each sensor. These revised sensor values allow a more rigorous approach to condition monitoring, which would otherwise expose process systems to greater risk when using raw sensor information. Sensor validation, a technique to analyze individual sensors in tandem with data reconciliation, is critical to setting a strong foundation for any analytics models to be deployed. These elaborate areas of work ensure a greater degree of success when deploying any solution that involves the use of sensor data.
Fault Detection
This is a mature area of work and uses solutions ranging from those that are driven entirely by domain knowledge, such as pump curves and detection of anomalies thereof, to those that rely only on historical sensor/maintenance/operations data for analysis. An anomaly or fault is defined as a deviation from ‘acceptable’ operation but the context and definitions need to be clearly understood when working with different clients. Faults may be related to equipment, quality, plant systems, or operability. A good business context and understanding of client requirements are necessary for the design and deployment of the right techniques. From basic tools that use sensor thresholds, run charts, and more advanced techniques such as classification, pattern analysis, regression, a wide range of solutions can be successfully deployed.
Early Warning Systems
The detection of process anomalies in advance helps in the proactive management of abnormal events. Improving actionability or response time allows faults to be addressed before setpoints/interlocks are triggered. The methodology varies across projects and there is no ‘one-size-fits-all’ approach. Problem complexity could range from using single sensor information as lead indicators (such as using sustained pressure loss in a vessel to identify a faulty gasket that might rupture) to far more complex methods of analysis.
Typical challenges faced in developing early warning systems are in the 100% detectability of anomalies but an even larger challenge is in filtering out false indications of anomalies. The detection of 100% of the anomalies and the robust filtering techniques are critical factors to consider for successful deployment.
Enhanced Insights for Fault Identification
The importance of detection and response time in the prevention of an event cannot be overstated. But what if an incident is not easy to detect or the propagation of the fault is too rapid to allow us any time for action? The first level involves using machine-driven solutions for detection such as computer vision models, which are rapidly changing the landscape. Using these models, it is now possible to improve prediction accuracies of processes that were either not monitored or used manual monitoring. The second is to integrate the combined expertise of personnel from various job functions such as technologists, operators, maintenance engineers, and supervisors. At this level of maturity, the solution is able to baseline with the best that current operations aim to achieve. The third and by far the most complex is to move more faults in the ‘detectable’ and actionable realm. One such case was witnessed in a complex process from the metal smelting industry. Advanced-Data Science techniques using a digital twin amplified signal responses and analyzed multiple process parameters to predict the occurrence of an incident ahead of time. By gaining order of magnitude improvement in response time, it was possible to move the process fault from an unavoidable to an avoidable and actionable category.
With the context provided above, it is possible to choose a modeling approach and customize the solutions to suit the problem landscape:
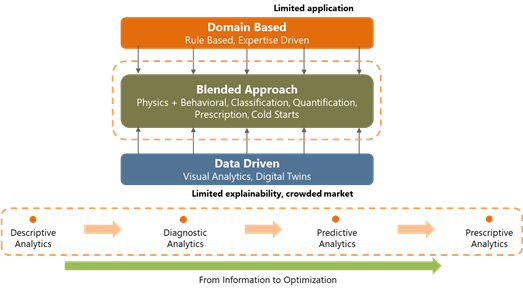
Different approaches to Data Analytics
Domain-driven solution
First-principles and the rule-based approach is an example of a domain-driven solution. Traditional ways of delivering solutions for manufacturing often involve computationally intensive solutions (such as process simulation, modeling, and optimization). In one of the difficult-to-model plants, deployment was done using rule engines that allow domain knowledge and experience to determine patterns and cause-effect relationships. Alarms were triggered and advisories/recommendations were sent to the concerned stakeholders regarding what specific actions to undertake each time the model identified an impending event.
Domain-driven approaches also come in handy in the case of ‘cold start’ where solutions need to be deployed with little or no data availability. In some deployments in the mechanical domain, the first-principles approach helped identify >85% of the process faults even at the start of operations.
Pure data-driven solutions
A recent trend seen in the process industry is the move away from domain-driven solutions due to challenges in getting the right skills to deploy solutions, computation infrastructure requirements, customized maintenance solutions, and the requirement to provide real-time recommendations. Complex systems such as naphtha cracking, alumina smelting which are hard to model have harnessed the power of data science to not just diagnose process faults but also enhance response time and bring more finesse to the solutions.
In some cases, domain-driven tools have provided high levels of accuracy in analyzing faults. One such case was related to compressor faults where domain data was used to classify them based on a loose bearing, defective blade, or polymer deposit in the turbine subsystems. Each of these faults was identified using sensor signatures and patterns associated with it. Besides getting to the root cause, this also helped prescribe action to move the compressor system away from anomalous operation.
These solutions need to bear in mind that the operating envelope and data availability covers all possible scenarios. The poor success of deployments using this approach is largely due to insufficient data that covers plant operations and maintenance. However, the number of players offering a purely data-driven solution is large and soon replacing what was traditionally part of a domain engineer’s playbook.
Blended solutions
Blended solutions for the maintenance of process systems combine the understanding of both data science and domain. One such project was in the real-time monitoring and preventive maintenance of >1200 HVAC units across a large geographic area. The domain rules were used to detect and diagnose faults and also identify operating scenarios to improve the reliability of the solutions. A good understanding of the domain helps in isolating multiple anomalies, reducing false positives, suggesting the right prescriptions, and more importantly, in the interpretability of the data-driven solutions.
The differentiation comes from using the combined intelligence from AI / ML models, domain knowledge and knowledge of deployment success are integrated into the model framework.
Customizing the toolkit and determining the appropriate modeling approach are critical to delivery. Given the uniqueness of each plant and problem and the requirement for a high degree of customization, makes the deployment of solutions in a manufacturing environment is fairly challenging. This fact is validated by the limited number of solution providers serving this space. However, the complexity and nature of the landscape need to be well understood by both the client and the service provider. It is important to note that not all problems in the maintenance space are ‘big data’ problems requiring analysis in real-time, using high-frequency data. Some faults with long propagation times can use values averaged over a period of time while other systems with short response time requirements may require real-time data. Where maintenance logs and annotations related to each event (and corrective action) are recorded, one could go with a supervised learning approach, but this is not always possible. In cases where data on faults and anomalies are not available, a one-class approach to classify the operation into normal/abnormal modes has also been used. Solution maturity improves with more data and failure modes identified over time.
A staged solution approach helps in bringing in the right level of complexity to deliver solutions that evolve over time. Needless to say, it takes a lot of experience and prowess to marry the generalized understanding with the customization that each solution demands.
Edge/IoT
A fair amount of investment needs to be made at the beginning of the project to understand the hardware and solution architecture required for successful deployment. While the security of data is a primary consideration, other factors such as computational power, cost, time, response time, open/closed-loop architecture are added considerations in determining the solution framework. Experience and knowledge help understand additional sensing requirements and sensor placement, performance enhancement through edge/cloud-based solutions, data privacy, synchronicity with other process systems, and much more.
By far, the largest challenge is witnessed on the data front (sparse, scattered, unclean, disorganized, unstructured, not digitized, and so on) that prevent businesses from seeing quick success. Digitization and creating data repositories, which set the foundation for model development, take a lot of time.
There is also a multitude of control systems, specialized infrastructure, legacy systems within the same manufacturing complex that one may need to work through. End-to-end delivery with the front-end complexity in data management creates a significant entry barrier for service providers in the maintenance space.
Maintenance cuts across multiple layers of a process system. The maintenance solutions vary as one moves from a sensor to a control loop, equipment with multiple control valves all the way to a flowsheet/enterprise layer. Maintenance across these layers requires a deep understanding of both the hardware as well as process aspects, a combination that is often hard to put together. Sensors and control valves are typically maintained by those with an Instrumentation background, while equipment maintenance could fall in a mechanical or chemical engineer’s domain. On the other hand, process anomalies that could have a plant-level impact are often in the domain of operations/technology experts or process engineers.
Data Science facilitates the development of insights and generalizations required to build understanding around a complex topic like maintenance. It helps in the generalization and translation of learnings across layers within the process systems from sensors all the way to enterprise and other industry domains as well. It is a matter of time before analytics-driven solutions that help maintain safe and reliable operations become an integral part of plant operations and maintenance systems. We need to aim towards the successes that we witness in the medical diagnostics domain where intelligent machines are capable of detecting and diagnosing anomalies. We hope that similar analytics solutions will go a long way to keep plants safe, reduce downtime and provide the best of operations efficiencies that a sustainable world demands.
Today, the barriers to success are in the ability to develop, a clear understanding of the problem landscape, plan end-to-end and deliver customized solutions that take into account business priorities and ROI. Achieving success at a large scale will demand reducing the level of customization required in each deployment – a constraint that is overcome by few subject matter experts in the area today.