In today’s data-driven world, we make critical business decisions based on data. But what happens when that data is wrong? Poor data quality isn’t just a minor inconvenience; it cascades across systems, leading to inaccurate analysis, significant unplanned rework, and a deep-seated lack of trust in data that sabotages the adoption of analytic tools.
For years, data quality (DQ) management has been a reactive, manual, and time-consuming process. Teams often discover issues only after they’ve already impacted downstream applications.
But what if we could change that? What if we could use the power of Generative AI to augment our data quality processes, making them proactive, automated, and intelligent? This is the promise of Augmented Data Quality (ADQ).
What is Augmented Data Quality?
Augmented Data Quality is a modern approach that uses AI-driven insights to automatically detect and address data quality issues. Instead of relying solely on manually written rules, an ADQ framework leverages Generative AI to understand your data and recommend dynamic DQ rules based on its findings.
This approach transforms the way organizations manage data. It helps clients move beyond manual rule writing and fragmented checks to automatically generate KPI-aware data quality rules and detect semantic segment–based anomalies. This shifts data issue detection from reactive to proactive, uncovering problems early to prevent cascading downstream impacts and restoring trust across BI and business teams.
The ADQ Architecture: An Intelligent, Agentic Approach
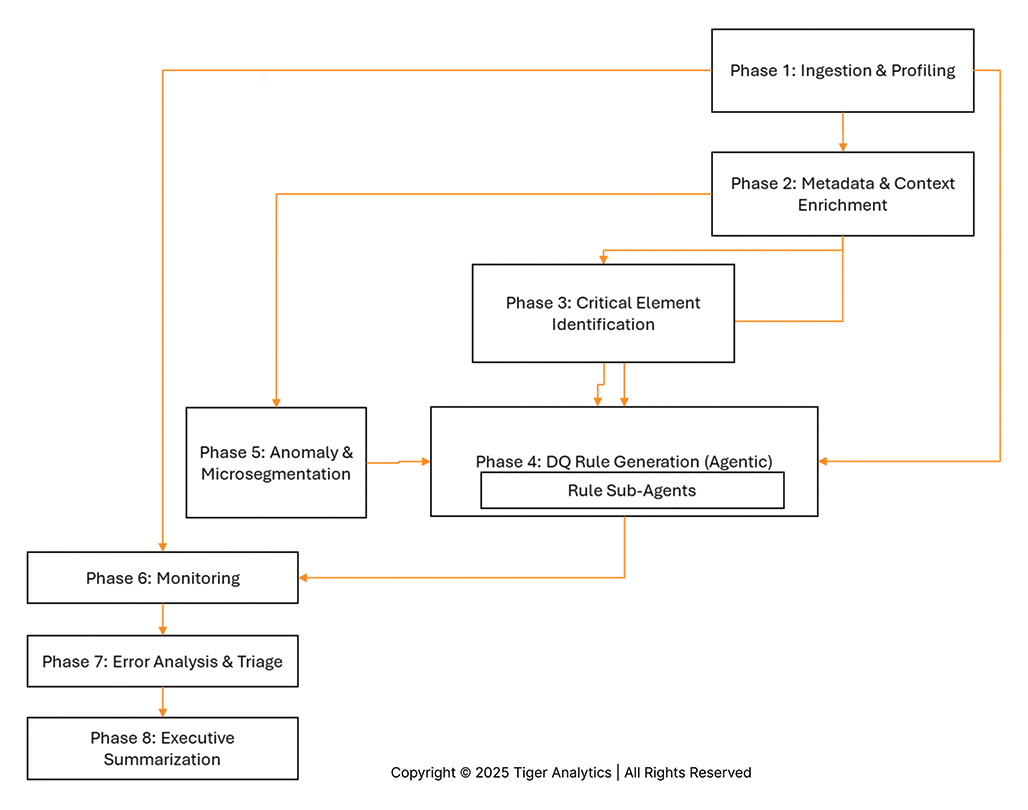
The power of this solution lies in its complete Agentic Architecture, which features different specialized agents for each task. This GenAI-powered, low-code/no-code solution enhances the entire data quality rule recommendation process.
Key features of this architecture include:
- LLM-Powered Recommendations: The system suggests dynamic DQ rules based on the enriched metadata.
- User Feedback Loop: It features an interactive interface that allows Data Analysts and Modelers to co-build and refine the rules. This enables continuous refinement of rules through direct user input.
- Visualization & Alerts: The framework provides custom dashboards and notifications for tracking data quality issues, enabling proactive monitoring.
- Modular & Extensible: The solution is built on a modular codebase, which allows for easy customization and integration according to enterprise-specific data governance standards and tools.
The power of this solution lies in its complete Agentic Architecture. Think of it not as a single tool, but as a collaborative team of specialized AI agents working together, with human experts providing critical validation at key steps.
The process flows through an assembly line of these specialized agents, augmented by human expertise:
- Profiling & Enrichment: A Data Profiler Agent scans the raw data to create a statistical report. This report, along with user-provided context and SME feedback, is used by the Enrich Data Dictionary Agent to build a context-rich dictionary—the foundation for all other agents.
- Identification: With a dictionary in hand, specialized agents identify Primary Keys (PK), Candidate Keys (CK), and most importantly Critical Data Elements (CDEs), using business rules and weightage defined by users. This tells the system what data matters most.
- Microsegmentation & Anomaly Detection: In parallel, the Generate Microsegments Agent identifies key business segments (e.g., “Japan – Weekly – Sales”). After a Human-in-the-Loop validation, the Anomaly Detection Engine profiles these segments and flags outliers. These anomalies are also validated by a human analyst before being sent to the rule engine.
- Core Rule Generation: This is the brain of the operation. The central DQ Rule Generation Agent orchestrates a team of sub-agents to build a comprehensive rule set:
- Technical DQ Rules Agent: Generates rules from the data profile (nulls, types, ranges).
- Natural Language DQ Rules Agent: Translates human-written rules (e.g., “phone must be 10 digits”) into executable code.
- STTM Driven DQ Rules Agent: Creates rules based on data lineage and mapping documents.
- KPI Driven DQ Rules Agent: Automatically writes new rules based on the validated anomalies from the previous step. All suggested rules are presented to a Data Steward for a final Human-in-the-Loop validation before being finalized.
- Monitoring & Insights: The finalized rules are deployed by DQ Monitoring Agents. When errors are found, the system doesn’t just report them; it triages them:
- An Error Insights Agent recommends cleansing strategies (e.g., “remove special characters”).
- An Impact Analysis Agent assesses the business impact (e.g., “address errors will affect shipments”).
- Finally, an Insight Agent aggregates all findings and uses an LLM to generate a high-level Executive Summary for business stakeholders.
This “glass box” approach, combining AI-driven automation with human-in-the-loop validation, ensures that the resulting data quality framework is not only powerful and efficient but also practical, trustworthy, and aligned with business priorities.
The Cornerstone of ADQ: Intelligent Data Dictionary Enrichment
Before any rules can be recommended, you must first understand the data. The Data Dictionary is the crucial first step in this process. It is essential for understanding the dataset, identifying Critical Data Elements (CDEs), and ultimately generating and finalizing the Data Quality rules.
However, creating a useful dictionary is incredibly challenging. Enterprise data is often locked in a wide variety of sources, from modern flat files and legacy databases to complex systems like Mainframes or SAP. Each source system requires a different approach to enrich the dictionary.
To solve this, we follow a tailor-made, Agentic approach to enrich the data dictionary. This isn’t a one-size-fits-all solution; it combines multiple agents based on the source, available information, and business context. This approach includes:
- Leveraging Pretrained LLM Knowledge
- Internet Search for public definitions
- Business Catalog Mapping and Semantic Matching
- Contextualization based on surrounding data
- Analyzing Historical Documentation, Technical Metadata, and Data Lineage
- Incorporating SME Feedback through a human-in-the-loop process
By orchestrating these agents, we can build a rich, accurate data dictionary that provides the semantic foundation needed for the Generative AI to recommend truly relevant and effective data quality rules.
Key Features of the ADQ Framework
This architecture delivers a comprehensive set of features designed to manage the entire data quality lifecycle.
Automated Data Quality Rule Recommendation
- Profiling & Metadata Enrichment: Automatically profiles data and enriches the metadata.
- Single & Multi-Column Rules: Recommends rules for individual columns (like type or null checks) and complex rules across multiple columns.
- Referential Integrity: Generates rules to check for referential integrity.
- Dynamic Rule Generation: Creates new DQ rules based on detected anomalies and STTM (Source to Target Mapping) logic.
- Format Conversion: Converts the generated rules into multiple executable formats, including Great Expectation, Spark Expectation, and SQL.
DQ Monitoring
- Categorized Metrics: Organizes DQ results and monitoring metrics by key dimensions like completeness, conformance, and consistency.
- Health Dashboards: Provides a health index for each dataset, along with trend charts for easy visualization.
- Alerting: Triggers alerts when DQ results fall below predefined thresholds.
- Workflow Integration: Seamlessly integrates DQ monitoring directly into existing ETL/ELT workflows.
Anomaly Detection
- Semantic Segmentation: Automatically identifies seasonal drivers to recommend semantic segmentation (microsegments).
- Natural Language Explanations: Flags anomalies with natural language tooltips, clearly explaining the expected vs. actual values.
- Pipeline Integration: Integrates anomaly detection logic directly into Spark-based pipelines and surfaces the results through dashboards.
- Feedback Loop: Enables a seamless process for monitoring, providing feedback, and refining the detection logic.
Case Study: Transforming DQ for a Global Athletic Leader
A global leader in athletic innovation and lifestyle operates at scale across digital, retail, and marketplace channels in over 190 countries. With increasing data volume and pipeline complexity, ensuring data quality becomes crucial. The organization aimed to move from manual, reactive data quality processes to a scalable, intelligent solution that can automatically detect anomalies, generate rules, and surface microsegment-level insights aligned with business needs.
The Business Problem
As the organization’s data volumes and pipeline complexity increased, ensuring data quality across global operations became a strategic imperative. Key challenges included:
- Manual Rule Definition: Quality checks were written manually, leading to inconsistent logic, duplicated efforts, and delayed coverage.
- Delayed Anomaly Detection: Issues often surfaced late in reporting cycles, impacting KPI trust and increasing operational rework. Identifying the root cause of data inconsistencies was time-consuming and reactive.
- Generic Profiling: Traditional profiling tools lacked semantic context and couldn’t infer business rules from metadata.
The objective was to introduce an intelligent, scalable data quality capability that could automatically generate context-aware rules, proactively detect anomalies, and provide targeted insights across high-impact business KPIs.
The Augmented Solution
The ADQ framework was deployed to provide an end-to-end, intelligent solution:
- Profiling & Metadata Enrichment: The system profiled 135 columns across 4 billion records using a custom profiling engine. It used custom-built, rich Generative AI techniques to generate data dictionaries and identify critical data elements.
- GenAI-Powered Rule Generation: It automatically generated single- and multivariate data quality rules using metadata, profiling insights, and business KPI context. These rules spanned completeness, conformance, and consistency dimensions. An interactive UI allowed Data Analysts and Domain users to customize and publish logic via UI and API.
- Microsegment Profiling Engine: The framework automatically identified seasonal drivers and correlated attributes per KPI. It then created granular microsegments by combining these with time dimensions (e.g., weekly, monthly). Each segment was evaluated for anomaly detection.
- Anomaly Detection at Microsegment Level: Applying semantic segmentation and statistical techniques, the system detected outliers for metrics like revenue and units. Anomalies were flagged with natural language tooltips, providing clarity on expected vs. actual values.
- Integrated Pipeline Execution: The new rules and anomaly logic were integrated directly into the client’s Spark-based pipelines and surfaced results through dashboards, enabling seamless monitoring, feedback, and refinement.
A Databricks Architecture
Let’s look at a concrete technical implementation. This diagram shows the ADQ development setup on Databricks.
Here’s how the components work together:
- Data Profiling: The flow begins with a Data Profiler This job reads data directly from Unity Catalog and writes its Profiled Output. This output, containing statistical insights about the data, is then fed into the core rule generation engine.
- DQ Rule Generation: This central block, running as Databricks Notebooks, is the brain of the operation. It uses a modern Python stack, including LangChain and LangGraph to build and orchestrate the AI agents, and LanceDB for efficient vector storage and search.
- Generative AI Engine: To perform its reasoning, the DQ Rule Generation block calls MOSAIC AI. This provides access to powerful foundational models and embedding models.
- Supporting Components: The entire process is supported by:
- Databricks Secrets to securely manage API keys and credentials.
- A Metastore (e.g., PostgreSQL) that stores and retrieves metadata, profile information, and the generated rules.
- A User feedback loop for validating the AI’s suggestions.
The final output is a set of validated Spark Expectations Rules, MicroSegments, and Anomalies, ready to be deployed into production pipelines.
The Real-World Impact
The impact of this new framework was immediate and transformative, moving the client from a reactive to a proactive DQ posture.
Data Quality Lifecycle
- Increased Efficiency: The system generated single & multivariate rules for 135 columns in under 8 minutes. It suggested microsegments for each KPI in approximately 3-4 minutes.
- Higher Agility: This enabled faster deployment of checks directly into pipelines, reducing the lag in detecting and resolving issues. It also helped users identify business-relevant columns and semantic groups of columns without detailed data analysis.
- Knowledge Reuse: The solution allowed for the reuse of dictionary and profile assets across datasets for consistency and reduced rework.
Anomaly Detection & Microsegment Insight
- Localized Detection: The framework’s power was proven in its specificity. For the KPI ‘Total Gross Sales USD’, microsegment-level anomalies were detected specifically in the Japan marketplace.
- Root Cause Visibility: Instead of just a pass/fail flag, natural language tooltips explained the anomaly with ranges, enabling quick triage and providing immediate root-cause visibility that was previously missing.
Ultimately, Augmented Data Quality, powered by Generative AI, transforms data governance from a reactive chore into an intelligent, proactive, and continuous process. It builds a reliable foundation of trust, ensuring your data is always ready and appropriate for business use.

