This post is about Kylin, its architecture, and the various challenges and optimization techniques within it. There are many “OLAP in Hadoop” tools available – open source ones include Kylin and Druid and commercial ones include Atscale and Kyvos. I have used Apache Kylin because it is better suited to deal with historical data when compared to Druid.
What is Kylin?
Apache Kylin is an open source distributed analytical engine that provides SQL interface and multidimensional analysis (OLAP) on Hadoop supporting extremely large datasets. It pre-calculates OLAP cubes with a horizontal scalable computation framework (MR, Spark) and stores the cubes into a reliable and scalable datastore (HBase).
Why Kylin?
In most of the use cases in Big Data, we see the challenge is to get the result of a query within a second. It takes a lot of time to scan a database and return the results. This is where the concept of ‘OLAP in Hadoop’ emerged to combine the strength of OLAP and Hadoop and hence give a significant improvement in query latency.
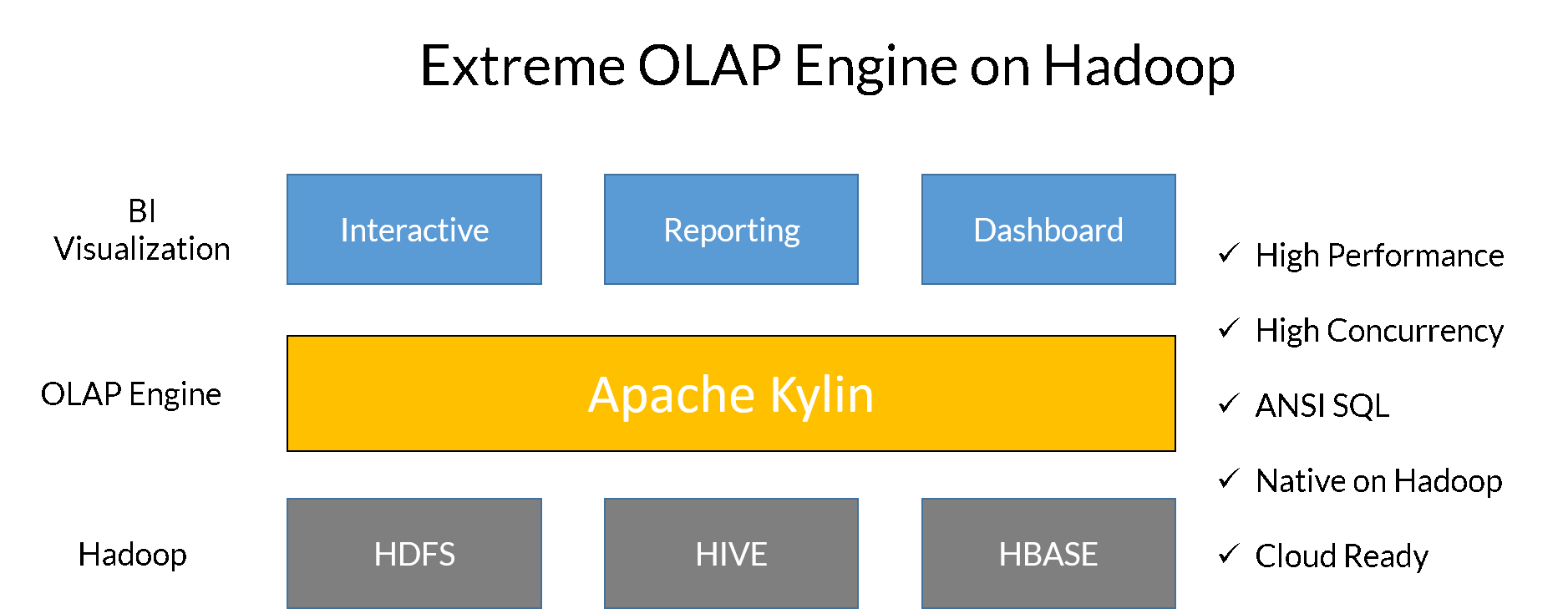
Source: Apache Kylin: Speed Up Cubing with Apache Spark with Luke Han and Shaofeng Shi
How it Works?
Below are the steps on how Kylin fetches the data and saves the results:
- First, it syncs the input source table. In most cases, it reads data from Hive.
- Next, it runs MapReduce/Spark jobs (based on the engine you select) to pre-calculate and generate each level of cuboids with all possible combinations of dimensions and calculate all the metrics at different levels
- Finally, it stores cube data in HBase where the dimensions are rowkeys and measures are column families.
Additionally, it leverages ZooKeeper for job coordination.
Kylin Architecture:
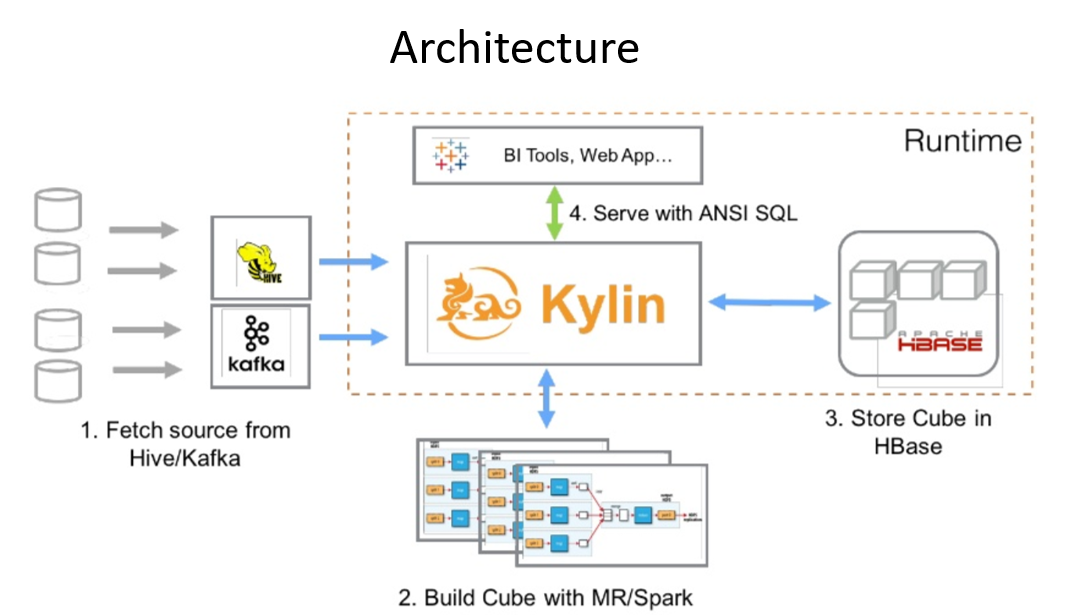
Source: Apache Kylin: Speed Up Cubing with Apache Spark with Luke Han and Shaofeng Shi
In Kylin, many cubing algorithms have been released and here are the three types of cubing:
- By layer
- By fast cubing = “In-mem”
- By layer on Spark
On submitting a cubing job, Kylin pre-allocates steps for both “by-layer” and “in-mem”. But it only picks one to execute and the other one will be skipped. By default, the algorithm is “auto” and Kylin selects one of them based on its understanding of the data picked up from Hive.
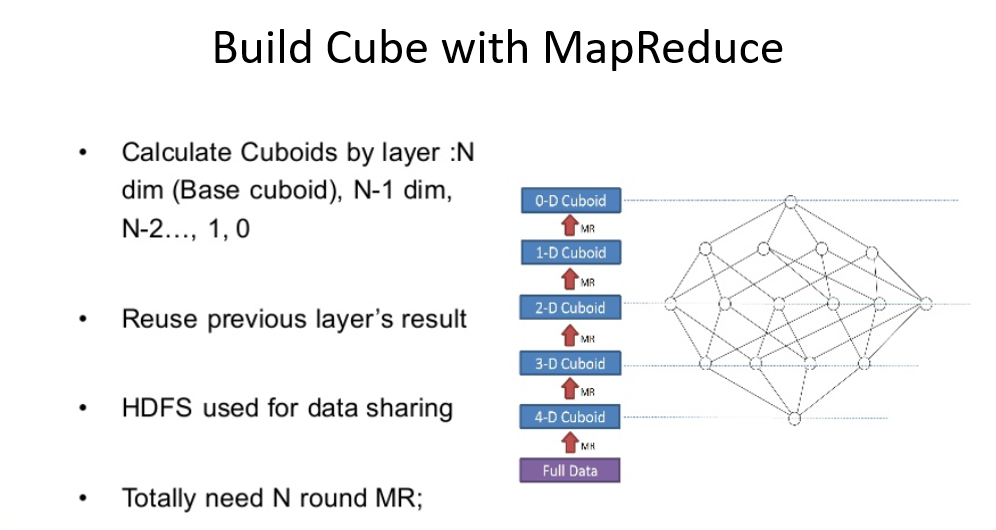
Source: Apache Kylin: Speed Up Cubing with Apache Spark with Luke Han and Shaofeng Shi
So far, we got a glimpse of how Kylin works. Now let us see the real challenges and how to fix them and also how to optimize the cube building time.
Challenges and Workaround to Solve:
- In Kylin 2.2, one cannot change the datatype of the measures column. By default, Kylin uses decimal(19,4) for the double type metric column. The workaround in order to change the datatype is to change the metadata of the cube by modifying it with the “metadata backup” and “restore” commands. (https://kylin.apache.org/docs/howto/howto_backup_metadata.html). After taking a backup, find the cube description in /cube_desc folder, find your cube, and then edit it. After the above changes are done, restart Kylin. Make sure to run the command below and restart Kylin as it expects that one will not manually edit the cube signature and hence this check: ./bin/metastore.sh refresh-cube-signature
- In Kylin 2.3.2, when we query ‘select * from tablename’, it displays empty/null values in the metric column. This is because Kylin only stores the aggregated values and will display values only when you invoke the ‘group by’ clause in the query. But if you need to get the result, you can use Kylin query push-down feature if a query cannot be answered by any cube. Kylin supports pushing down such queries to backup query engines like Hive, SparkSQL, Impala through JDBC.
- Sometimes, the jobs build fails continuously even if you discard and run again or resume it. The reason is that ZooKeeper may already have a Kylin directory, so the workaround is to remove Kylin from ZooKeeper, and then the cube builds successfully.
Summary
The key takeaway from this post is that Apache Kylin significantly improves the query latency provided that we control the unnecessary cuboid combinations using the “Aggregation Group”(AGG) feature Kylin provides. This feature helps in reducing the cube build time and querying time as well.
Hope this post has given some valuable insights about Apache Kylin. Happy Learning!
References- Apache Kylin: Speed Up Cubing with Apache Spark with Luke Han and Shaofeng Shi




