Authors: Chenyang Shi, Nishant Soni, Danish Azam
Within the dynamic world of the pharmaceutical industry, finding the right balance between meeting patient needs and maintaining cost-effective inventory control is key. Given the short shelf-life of many pharmaceutical products and their direct impact on human health, accurate sales forecasting is not just an advantage—it’s essential for the industry’s success.
Tiger partnered with a leading global pharmaceutical company in the development of an AI-based sales prediction software product for one of their blockbuster drugs. Here is a recap of our key learnings.
From Excel to Python – Upgrading from spreadsheets to web-based applications
To predict the projected sales revenue of the drug, into the future (e.g., next twenty years), the client’s forecasting team were developing Excel spreadsheets with both model logic and actionable user interface (UI) included within the same files. These Excel models were then rolled out to sales representatives for prediction use in their specific geographical locations. As a final step, all the Excel sheets were filled out and emailed to the headquarters.
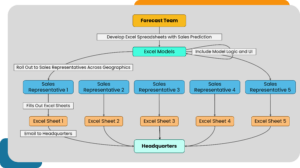
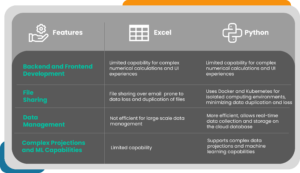
While Excel is one of the most accessible and user-friendly data management tools, it does have a few limitations when it comes to scaling up the complex number crunching involved in drug sales revenue forecasting and prediction. While doing a deep dive into the client’s sales revenue projection process, we found these opportunities for improvement.
To support the pharma company’s growing data volumes and need for complex projections, advanced data visualizations and ML capabilities, we adopted a Python-based approach. We worked on translating the Excel-based forecasting logic to Python programs for optimized calculation performance whereas the UI creation is handled by the ipywidgets / ipysheet / ipyvuetify / Voilà ecosystem [1] that provides intuitive navigation and easy-to-use interface. We solved the issue of the duplicated model (previously it was Excel and here it was the development code) by leveraging the power of microservices tools such as Docker and Kubernetes where each user could have their own pod (i.e. the computing environment) that was isolated from other users. Through this approach the data is now collected and saved in real time to the database hosted on the cloud.
Through this entire development process, we helped our client build an efficient solution and these were our key takeaways:
Lesson 1: Open communication – The compass for success
One of the most important features of a successful development process is continuous, open communication with all key players: managers, directors, forecasting teams, and fellow developers. This ensures that all the relevant stakeholders are on the same page, are aware of the hurdles and obstacles, and so can prepare for any possible challenges.
Throughout this project, Managers and directors sketched the project’s blueprint and defined expectations; the forecasting team refined the prediction strategies; fellow developers shared their insights and experiences to tackle coding hurdles.
This collaboration was instrumental in helping us successfully craft and deliver the software product.
Lesson 2: ipy-ecosystem and Voilà – Your toolbox for quick web applications
Python-based tools like ipywidgets, ipysheet, and ipyvuetify allow us work in Jupyter Notebook, making it easy to create different parts of a web app like buttons, dropdown menus, and sliders. We can also arrange these parts into tabs for easy navigation. With a tool called Voilà, we turn our notebook into a web app. Here’s an example where we used sliders to interact with figures.[2]
Lesson 3: A modular code design can help with product development and management of releases
We adopted a modular code design approach right from the project’s inception. We created a series of helper functions that can be reused across different workstreams. For instance, to build the front-end dashboard, we have developed handy scripts to quickly generate tables and tabs, making the UI design equivalent to building Lego blocks. The same modular design mindset is particularly useful when it comes to maintaining the code for product releases. Each release has its own separate and isolated code base, with other commonly used code shared between the releases.
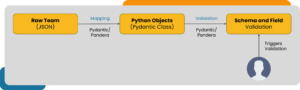
Lesson 4: Data validation with Pydantic and Pandera will ensure the integrity of your data pipeline
Pydantic and Pandera are powerful Python libraries [3] for data validation and data mapping, which makes the data processing pipeline more readable and robust. Specifically, Pydantic maps the incoming data into a class-attributes-based structure and validates them with user-specified checks. On the other hand, Pandera maps data into data frame-like objects and validates each field of the data frame at run time. Both data validation and mappings processes are critical in production-grade data pipelines. We have used both libraries to map data stored in JSON format into class attributes which will automatically trigger the validation process and throw meaningful exception messages if invalid data are detected.
Lesson 5: Jenkins for CI/CD – A smooth pathway for code development
Jenkins, the open-source automation tool, was a game-changer in our software development process. It facilitated continuous integration and continuous deployment (CI/CD), automating routine tasks related to building, testing, and deploying code changes across various testing stages. We’ve found that Jenkins offers a simple way to set up a CI/CD environment for almost any combination of languages and source code repositories using pipelines, as well as automating other routine development tasks.
In our code development, we set up a CI/CD pipeline to automatically pick up the latest code change at the main branch at Bitbucket and deploy it to various stages of testing such as Development (DEV), System Integration Test (SIT), User Acceptance Test (UAT) and Production (PROD).
![A typical example of CI/CD pipeline [4].](https://www.tigeranalytics.com/wp-content/uploads/2023/06/Pharma-04-Graphics-300x173.png)
Lesson 6: Python for speed optimization – The secret to seamless user experience
When using a web-based application, the user generally expects a smooth UI experience, that is, whenever a button is clicked, the updated contents are displayed in a reasonably short amount of time. One computation bottleneck we found in the Excel logic, however, requires ~10.5 minutes for a single calculation, which is clearly unacceptable. To mitigate this issue, we have leveraged the power of Python in optimizing numerical computation. Specifically, we
(1) identified and removed the unnecessary calculation in a cumbersome Python for loop
(2) deleted the large and intermediate Python objects that are used only once from the memory
(3) used vectorized computation via NumPy whenever possible.
In the end, we managed to reduce the calculation time from ~10.5 minutes to 9 seconds
Lesson 7: The benefits of adapting to an assumption-based prediction approach
We worked with a new approach for predicting drug sales revenue – the assumption-based prediction model. In contrast to the traditional forecasting paradigm where the prediction projects the historical data into the future, the assumption-based approach is a hybrid forecasting technique where historical data may or may not exist. Here we have multiple stages where calculations are done based on assumptions derived from domain expertise and intuitions. It is an open-box model which can be tweaked at any stage by the forecasters based on the specific market information from their geographical locations. A flow diagram of the assumption-based prediction is shown below.
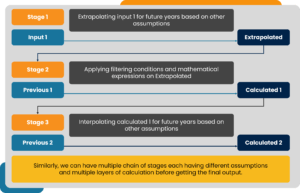
We’ve seen that developing a robust and user-friendly software product involves striking a delicate balance between project budgets, SLAs, and practical considerations along with managing the technical aspects of creating, implementing, and testing a bug-free product. Regular and timely, regular communication across stakeholders while taking stock of all the technical considerations will ensure a successful product release.
References:
[1] ipywidgets https://ipywidgets.readthedocs.io/en/stable/; ipysheet https://ipysheet.readthedocs.io/en/stable/; ipyvuetify https://ipyvuetify.readthedocs.io/en/latest/; Voilà https://voila.readthedocs.io/en/stable/.
[2] https://github.com/voila-dashboards/voila-vuetify
[3] pydantic https://docs.pydantic.dev/; pandera https://pandera.readthedocs.io/en/stable/.
[4] https://www.wallarm.com/what/what-is-ci-cd-concept-how-can-it-work.

