Every claim tells a story, it just isn’t always linear. So insurance adjusters sift through police records, medical reports, witness statements to build their case file. But piecing together the story to make the right call with speed and precision at scale? That’s far from elementary.
We partnered with a Fortune 500 firm to explore GenAI-powered content summarization techniques that turn sprawling document trails into concise, information-rich insights, helping adjusters make decisions faster. Claims processing is just one example. Industries across the board need systems that can deliver and execute with precision despite changing requirements. In Generative AI, this pressure shows up in the scaling phase. Models that work in controlled pilots can run into challenges when pushed to enterprise volumes and real-world variability.
At Tiger Analytics, we worked with clients to embed GenAI foundational models into production-grade ML Engineering and MLOps. We found that content summarization is one area where the payoff is tangible, condensing thousands of pages into focused snippets, reducing manual effort and improving processing time, often with higher accuracy compared to earlier approaches.
In the following sections, we unpack how we approach large-scale content summarization, Amazon Bedrock’s architecture, its constraints, and a quick comparison with other tools. Whether you’re a data scientist, ML engineer, AI architect, or technology leader, you’ll find practical guidance and architectural considerations for deploying GenAI solutions in complex environments.
A Quick Guide to Amazon Bedrock Architecture
In our work, we’ve observed that Amazon Bedrock streamlines the implementation of GenAI applications by simplifying invocation to a host of high-performing foundations models through a simple interface. Additionally, it provides tools for fine-tuning models and building agents with proper guardrails, supporting control and reliability. Its architecture comprises the following key facets:
- Foundation Models (FMs): Bedrock provides access to a variety of FMs, including those from AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon’s own Nova.
- API Layer: The Bedrock API simplifies access with a uniform interface for invoking backend foundation models.
- Features: Apart from invocation, Bedrock supports knowledge bases to implement RAG solutions, enables fine-tuning with customer data, and includes AgentCore for AI agents development.
- Security and Privacy: Bedrock offers robust security features such as data encryption (at rest and in transit), guardrails, VPC support, private endpoints (AWS PrivateLink), and access control via IAM. These features ensure that sensitive information is protected and private data is not used to train the base models.
Identifying the Right Content Summarization Pattern in Bedrock
Depending on the specific requirements of the application, there are several architectural patterns within Amazon Bedrock that can be employed for content summarization:
- Direct Summarization: The simplest approach involves directly invoking an FM through the Bedrock API (using SDKs or AWS CLI) and sharing the text to be summarized as input. The FM processes the input and generates a summary, which is then returned to the application. This is suitable for straightforward summarization tasks with reasonably sized input texts.
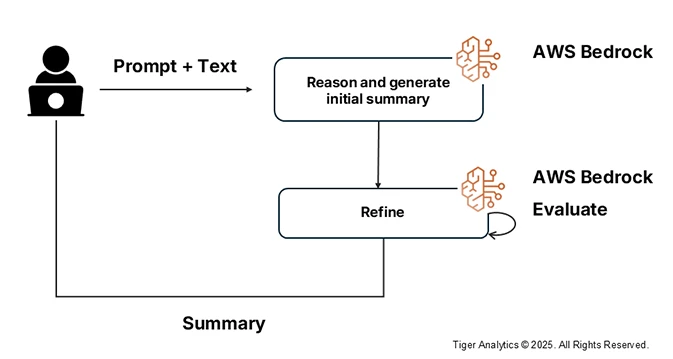
- Iterative Summarization: For more complex summarization tasks, we employ iterative summarization. Here, the document is split into sections. The first section is summarized then iteratively the summary is improved based on data from consecutive sections.
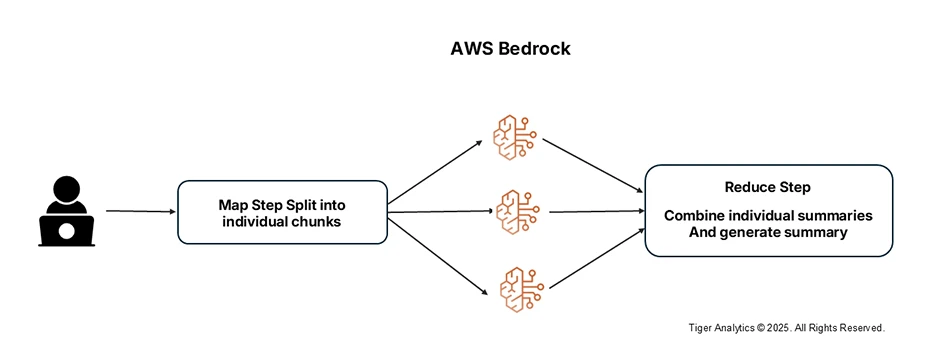
- Map-Reduce Summarization: The map-reduce method is effective for very large documents that exceed the context window of the LLM. The method breaks the document into chunks, generating summaries for individual chunks (the map step) and combining them into a single comprehensive summary (the reduce step).
How to Build Pipeline Architecture for Summarization on AWS?
For complex summarization workflows, we’ve found that AWS services can be stitched together to construct a pipeline architecture. Here’s how we build for map-reduce summarization:
- Amazon S3 for storing input documents, intermediate and output summaries.
- ECS-based processing units for preprocessing and chunking large corpus of text.
- AWS Lambda for pre-processing text, chunking, orchestrating FM invocations via the Bedrock API, and post-processing summaries.
- Amazon DynamoDB for storing metadata.
- Amazon API Gateway for exposing summarization functionality as a REST API.
- AWS Step Functions to orchestrate multi-step summarization processes (like chunking, parallel summarization, and final combination).
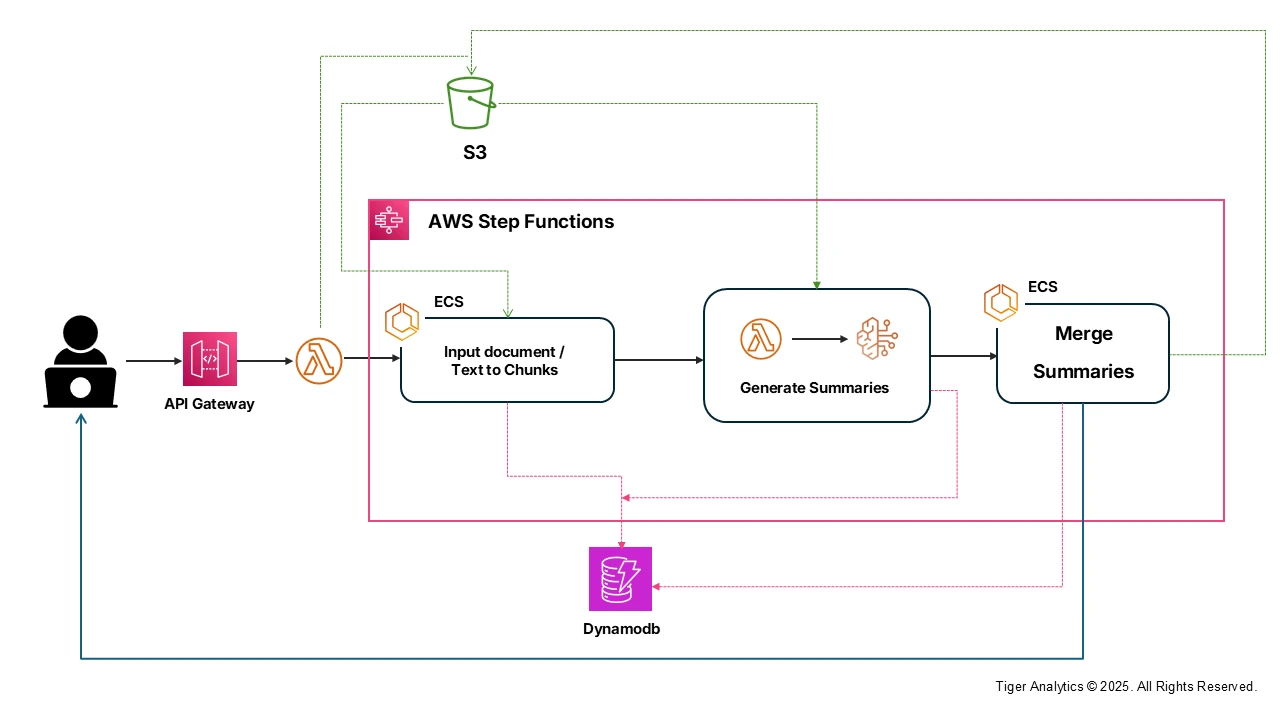
A critical aspect of the above architecture is the parallel invocation of bedrock to generate summaries. But here’s the catch: GenAI applications especially at scale, can hit the tokens per minute and requests per minute limitations imposed by AWS Bedrock.
Based on specific models and cost type, these limits can cap the number of files that can be processed in a given minute. Since summarization typically deals with a large number of tokens, this can add up quickly and lead to issues such as throttling.
Here’s how we can mitigate this:
- Limit the number of parallel calls to Bedrock. This is closely tied to business requirements and SLA. Strike a balance between how soon the documents need to be processed versus how many calls Bedrock can handle without triggering throttling.
- Another approach is at a code level with intelligent retry mechanisms. Implement exponential backoff with jitter. This allows for randomised waiting times between multiple calls to the Bedrock, helping the system recover smoothly from throttling.
We have below is a code example on how to handle throttling issues with Bedrock. Here, the tenacity package is used to implement the random exponential backoff in case of a ClientError or a ReadTimeOutError
import boto3
import json
import logging
import botocore
from botocore.exceptions import ClientError
from tenacity import (
retry,
stop_after_attempt,
wait_random_exponential,
retry_if_exception_type,
)
@retry(
stop=stop_after_attempt(3),
wait=wait_random_exponential(multiplier=3, min=1, max=10),
reraise=True,
retry=retry_if_exception_type((
botocore.exceptions.ClientError,
botocore.exceptions.ReadTimeoutError,
)),
)
def run_summary():
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
try:
bedrock_runtime = boto3.client(service_name='bedrock-runtime')
model_id = 'anthropic.claude-3-sonnet-20240229-v1:0'
system_prompt = "You are a helpful assistant that summarizes paragraphs concisely."
max_tokens = 500
input_text= ('''Amazon Bedrock streamlines implementation of Gen AI applications by simplifying invocation to a host of high performing foundations models through a simple interface. It provides tools for fine-tuning models and building agents with proper Guardrails.Its architecture comprises the following key facets:
Foundation Models (FMs): Bedrock provides access to a variety of FMs, including those from AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon itself (Nova).
API Layer:A Bedrock API that simplifies access to multiple models in the backend with a uniform method of invoking the backend foundation models.
Customization and enhancements: Apart from invocation, bedrock supports knowledge bases to implement RAG solutions, fine tuning with customer data, AgentCore for AI agents development.
Security and Privacy: Amazon Bedrock offers security features such as data encryption (at rest and in transit),Guardrails, VPC support, private endpoints (AWS PrivateLink), and access control via IAM, ensuring that sensitive information is protected and data is not used to train the base models.''' )
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": max_tokens,
"system": system_prompt,
"messages": [
{
"role": "user",
"content": f"Please summarize the following paragraph:\n\n{input_text}"
}
]
})
response = bedrock_runtime.invoke_model(body=body, modelId=model_id)
response_body = json.loads(response.get("body").read())
print("Summary of the Input text:")
print(json.dumps(response_body, indent=4))
except ClientError as err:
error_code = err.response['Error']['Code']
error_message = err.response['Error']['Message']
# If throttling then reraise so that retry is triggered
if error_code == 'ThrottlingException':
logger.warning(f"ThrottlingException encountered: {error_message}. Retrying with tenacity...")
raise
# Gracefully consume other errors
elif error_code == 'ValidationException':
logger.error(f"Validation error: {error_message}. Check your inputs.")
elif error_code == 'AccessDeniedException':
logger.error(f"Access denied: {error_message}. Check your permissions.")
else:
logger.error(f"ClientError {error_code}: {error_message}")
print(f"Error {error_code}: {error_message}")
except Exception as e:
logger.error(f"Unexpected error: {str(e)}")
print(f"An unexpected error occurred: {str(e)}")
if __name__ == "__main__":
run_summary()
Limitations of AWS Bedrock
When scaling workloads on AWS Bedrock, we run into a few limitations that can affect performance and throughput:
- Lack of high-performing native models keeps the cost of inference high while also limiting quotas with reference to tokens per minute and requests per minute.
- With inconsistent quotas across multiple regions and on-demand pricing, there is a risk of throttling as model inference load is shared across the region.
- Granular control and access to provider APIs (for example: Anthropic) is restricted in some cases.
How Does Bedrock Compare with Other Platforms?
Content summarization at scale is not a one-size-fits-all game. Amazon Bedrock, Snowflake Cortex AI, and Google Vertex AI each take a different approach with trade-offs in model options, ease of integration, scalability and cost. The information presented here is based on official product descriptions and documentation provided by the vendors. Here’s how they compare across metrics:
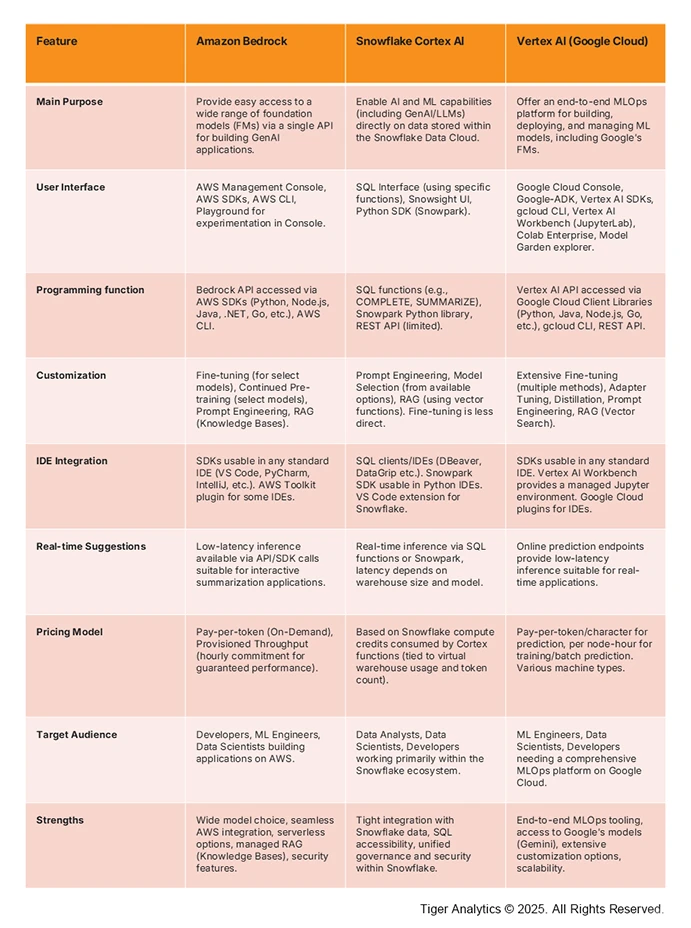
Mitigating the Scaling Challenge in Content Summarization
Scaling GenAI summarization is about anticipating challenges, and adjusting your strategy as requirements evolve. Amazon Bedrock offers enterprises strong building blocks: multiple foundation models, unified APIs, and robust security features that can streamline workflows, reduce manual effort, and accelerate decision-making across industries. The pipeline architecture shared in this blog can serve as a baseline that can be fine tuned to industry-specific use cases.
While Bedrock has clear strengths when it comes to model choice, integration, and managed services, its limitations, such as quota variability and the absence of high-performing native models, suggest that it delivers the most impact when paired with the right use case. Though strong contenders and alternatives are fast emerging, Bedrock’s strengths make it a compelling choice for organizations already invested in the AWS ecosystem or seeking a secure, extensible platform for GenAI-powered content summarization.
References
https://aws.amazon.com/bedrock
https://cloud.google.com/vertex-ai
https://www.snowflake.com/en/product/features/cortex
https://python.langchain.com/docs/how_to/summarize_refine
https://cloud.google.com/blog/products/ai-machine-learning/long-document-summarization-with-workflows-and-gemini-models
https://docs.snowflake.com/en/sql-reference/functions/summarize-snowflake-cortex
https://aws.amazon.com/blogs/machine-learning/techniques-for-automatic-summarization-of-documents-using-language-models
https://journalwjarr.com/sites/default/files/fulltext_pdf/WJARR-2025-2382.pdf
https://github.com/aws-samples/amazon-bedrock-architectures/tree/main/Architectures/Summarization/Summarization_API




