Introduction
When dealing with data, the main factor to be considered is the quality of data. Especially in the Big data environment, data quality is critical. Having inaccurate or flawed data will produce incorrect results in data analytics. Many developers test the data manually before training their model with the available data. This is time-consuming, and there are possibilities of committing mistakes.
Deequ
Deequ is an open-source framework for testing the data quality. It is built on top of Apache Spark and is designed to scale up to large data sets. Deequ is developed and used at Amazon for verifying the quality of many large production datasets. The system computes data quality metrics regularly, verifies constraints defined by dataset producers, and publishes datasets to consumers in case of success.
Deequ allows us to calculate data quality metrics on our data set, and also allows us to define and verify data quality constraints. It also specifies what constraint checks are to be made on your data. There are three significant components in Deequ. These are Constraint Suggestion, Constraint Verification, and Metrics Computation. This is depicted in the image below.
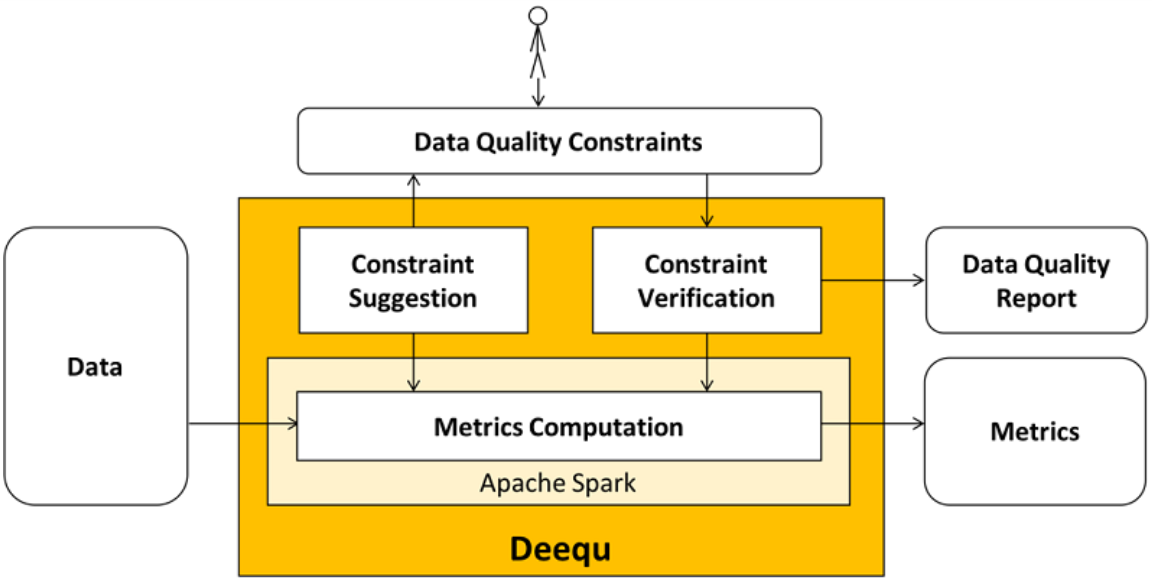
This blog provides a detailed explanation of these three components with the help of practical examples.
1. Constraint Verification: You can provide your own set of data quality constraints which you want to verify on your data. Deequ checks all the provided constraints and gives you the status of each check.
2. Constraint Suggestion: If you are not sure of what constraints to test on your data, you can use Deequ’s constraint suggestion. Constraint Suggestion provides a list of possible constraints you can test on your data. You can use these suggested constraints and pass it to Deequ’s Constraint Verification to check your data quality.
3. Metrics Computation: You can also compute data quality metrics regularly.
Now, let us implement these with some sample data.
For this example, we have downloaded a sample csv file with 100 records. The code is run using Intellij IDE (you can also use Spark Shell).
Add Deequ library
You can add the below dependency in your pom.xml
<dependency>
<groupId>com.amazon.deequ</groupId>
<artifactId>deequ</artifactId>
<version>1.0.2</version>
</dependency>
If you are using Spark Shell, you can download the Deequ jar as shown below-
wget
https://repo1.maven.org/maven2/com/amazon/deequ/deequ/1.0.1/deequ-1.0.2.jar
Now, let us start the Spark session and load the csv file to a dataframe.
val spark = SparkSession.builder()
.master(“local”)
.appName(“deequ-Tests”).getOrCreate()
val data = spark.read.format(“csv”)
.option(“header”,true)
.option(“delimiter”,”,”)
.option(“inferschema”,true)
.load(“C:/Users/Downloads/100SalesRecords.csv”)
data.show(5)
The data has now been loaded into a data frame.

data.printSchema

Schema
Note
Ensure that there are no spaces in the column names. Deequ will throw an error if there are spaces in the column names.
Constraint Verification
Let us verify our data by defining a set of data quality constraints.
Here, we have given duplicate check(isUnique), count check (hasSize), datatype check(hasDataType), etc. for the columns we want to test.
We have to import Deequ’s verification suite and pass our data to that suite. Only then, we can specify the checks that we want to test on our data.
import com.amazon.deequ.VerificationResult.checkResultsAsDataFrame
import com.amazon.deequ.checks.{Check, CheckLevel}
import com.amazon.deequ.constraints.ConstrainableDataTypes
import com.amazon.deequ.{VerificationResult, VerificationSuite}//Constraint verification
val verificationResult: VerificationResult = {
VerificationSuite()
.onData(data) //our input data to be tested
//data quality checks
.addCheck(
Check(CheckLevel.Error, “Review Check”)
.isUnique(“OrderID”)
.hasSize(_ == 100)
.hasDataType(“UnitPrice”,ConstrainableDataTypes.String)
.hasNumberOfDistinctValues(“OrderDate”,_>=5)
.isNonNegative(“UnitCost”))
.run()
}
On successful execution, it displays the below result. It will show each check status and provide a message if any constraint fails.
Using the below code, we can convert the check results to a data frame.
//Converting Check results to a DataFrame
val verificationResultDf = checkResultsAsDataFrame(spark, verificationResult)
verificationResultDf.show(false)

Constraint Verification
Constraint Suggestion
Deequ can provide possible data quality constraint checks to be tested on your data. For this, we need to import ConstraintSuggestionRunner and pass our data to it.
import com.amazon.deequ.checks.{Check, CheckLevel}
import com.amazon.deequ.suggestions.{ConstraintSuggestionRunner, Rules}//Constraint Suggestion
val suggestionResult = {
ConstraintSuggestionRunner()
.onData(data)
.addConstraintRules(Rules.DEFAULT)
.run()
}
We can now investigate the constraints that Deequ has suggested.
import spark.implicits._
val suggestionDataFrame = suggestionResult.constraintSuggestions.flatMap {
case (column, suggestions) =>
suggestions.map { constraint =>
(column, constraint.description, constraint.codeForConstraint)
}
}.toSeq.toDS()
On successful execution, we can see the result as shown below. It provides automated suggestions on your data.
suggestionDataFrame.show(4)

Constraint Suggestion
You can also pass these Deequ suggested constraints to VerificationSuite to perform all the checks provided by SuggestionRunner. This is illustrated in the following code.
val allConstraints = suggestionResult.constraintSuggestions
.flatMap { case (_, suggestions) => suggestions.map { _.constraint }}
.toSeq
val generatedCheck = Check(CheckLevel.Error, “generated constraints”, allConstraints)//passing the generated checks to verificationSuite
val verificationResult = VerificationSuite()
.onData(data)
.addChecks(Seq(generatedCheck))
.run()
val resultDf = checkResultsAsDataFrame(spark, verificationResult)
Running the above code will check all the constraints that Deequ suggested and provide the status of each constraint check, as shown below.
resultDf.show(4)

Metrics Computation
You can compute metrics using Deequ. For this, you need to import AnalyzerContext.
import com.amazon.deequ.analyzers._
import com.amazon.deequ.analyzers.runners.AnalyzerContext.successMetricsAsDataFrame
import com.amazon.deequ.analyzers.runners.{AnalysisRunner, AnalyzerContext}//Metrics Computation
val analysisResult: AnalyzerContext = {
AnalysisRunner
// data to run the analysis on
.onData(data)
// define analyzers that compute metrics .addAnalyzers(Seq(Size(),Completeness(“UnitPrice”),ApproxCountDistinct(“Country”),DataType(“ShipDate”),Maximum(“TotalRevenue”)))
.run()
}
val metricsDf = successMetricsAsDataFrame(spark, analysisResult)
Once the run is successful you can see results as below.
metricsDf.show(false)
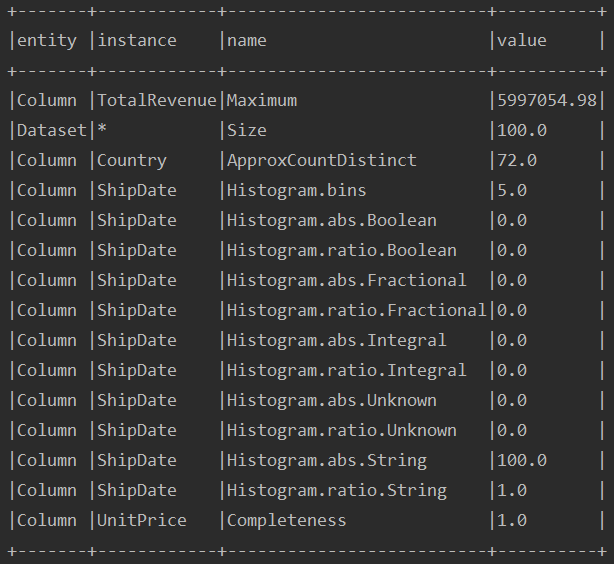
Metrics Computation
You can also store the metrics that you computed on your data. For this, you can use Deequ’s metrics repository. To know more about this repository, click here.
Conclusion
Overall, Deequ has many advantages. We can calculate data metrics, define, and verify data quality constraints. Even large datasets that consist of billions of rows of data can be easily verified using Deequ. Apart from Data quality checks, Deequ also provides Anamoly Detection and Incremental metrics computation.




