Modern data warehouses demand petabytes of storage and optimized techniques to run complex analytic queries. The traditional methods are comparatively less efficient and not cost-effective enough to meet current data warehousing needs. Many inexpensive cloud solutions are available to build data warehouse performance and support parallel query execution.
Modern cloud data warehouse solutions like BigQuery, Snowflake, and Redshift enable you to:
- Extract data from various heterogeneous sources into a data warehouse
- Implement data scrubbing and transformation on the source datasets
- Assess a visualization tool that can use the warehouse for discovery and insight
Though there are many tools available in the market, the below-curated stack represents the best Extract, Load, Transform (ELT) solution:
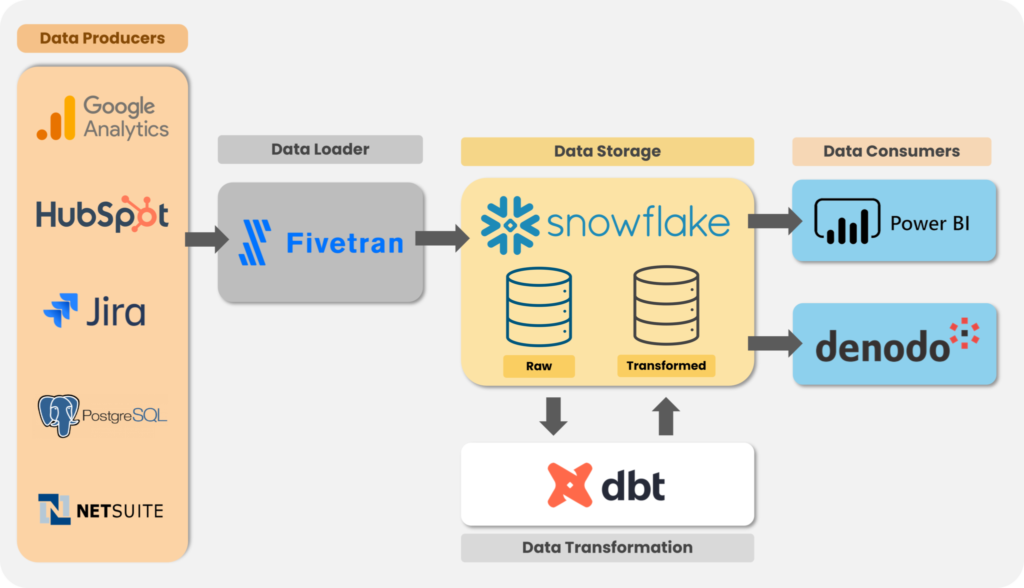
On your left, you will see data sources (a few samples) that produce data.
Fivetran extracts and loads data from different sources into the target. Once data is loaded in the storage layer, i.e., Snowflake, to tidy and alter the data, a transformation tool called dbt is used. This allows you to convert raw source data into an ideal ‘data warehouse native’ format that can be easily used for analysis. Then, Power BI and denodo provide a visualization and virtualization layer for running queries against Snowflake.
Fivetran is an ELT tool that helps you merge data from heterogeneous sources to manage directly from your internet browser. It has 160+ connectors for data integration, including sources for SaaS applications, databases, events, etc. Also, with Fivetran Transformations, customers can orchestrate scrubbing, testing, transformation, modeling, and documentation of data sets.
Fivetran integrated with the Open-Source software dbt Core in September 2020, making the transformations for dbt Core available. So, you can take advantage of a best-in-class automated cloud data integration experience in a single environment. When you use the ELT paradigm (using dbt) in Snowflake, the transformations are purely written in SQL. Hence, with dbt, you can articulate all your analytical logic with basic select statements that analysts are familiar with.
Each of these select statements is referred to as a model. dbt manages all the work to materialize these into the data warehouse. It also manages the dependencies among the models. So, if you have an orders model that joins an orders table to a product table, this model can be reused in additional models.
Other key benefits for ELT workflows are:
- Automated documentation – Create documentation and illustrations of the SQL models you have created and the dependencies between models.
- Automated testing – Specify tests that can be performed, as straightforward as checking that a column contains no nulls to confirming referential integrity between tables.
- Collaboration – Commit to a version control system like Git – allowing large teams to contribute to the transformation process.
How can you use dbt in Fivetran?
dbt manages the compilation of the code used to transform the data in the data warehouse. But this code needs to be often triggered on a schedule. As a Fivetran customer, you can use dbt-core (Fivetran-dbt Transformation), which is free and open source – therefore, handling the scheduling of transformations and logging/altering if any issues occur.
Never worked with dbt Core before? Then, get started with setting up your dbt environment in one of these ways!
- dbt Cloud: This is a web-based Integrated Development Environment (IDE) hosted by dbt Labs. It requires the least effort and offers many features like scheduling jobs, CI/CD, and alerts. The best part is it is free (dbt-pricing) via the Developer plan.
- dbt CLI: This option allows you to interact directly with dbt Core by installing it. There are multiple options to install dbt CLI (refer here). You also get to experiment with the various dbt commands and work in your IDE of choice.
To allow dbt to interact with your data warehouse (for example- Snowflake), you need the required login credentials, as explained in the below links.




Fivetran can run dbt projects created with either dbt Cloud or dbt CLI. The high-level steps to run dbt Transformation from Fivetran are as follows:
- Models are created in a dbt Core project. dbt then compiles these models into SQL statements that will transform the data in the data warehouse.
- This dbt project is then published to a Git repository like GitHub. This centralizes the code in a single source of truth (dbt Core) repository and allows different teams to collaborate on the project. In addition, it can be analyzed and evaluated before being pushed to live.
- Fivetran transformation needs to be configured with GitHub pointing to the code repository branch. It will then pull the most recent copy of the transformations (dbt project).
- A schedule in Fivetran will periodically execute the SQL code in your Snowflake instance.

Fivetran provides two types of transformations for dbt Core:
- Scheduled in Fivetran (advised): Fivetran connects to your Git provider and runs your dbt models in your destination. It is based on the schedule you choose in the Fivetran dashboard. It syncs your dbt models from your Git provider every few minutes to ensure that you are up to date. Run your dbt models in your destination according to your schedule in the Fivetran dashboard. You can configure integrated scheduling to trigger the Fivetran Transformations as soon as the destination data is updated. It helps reduce data latency and ensures that data is quickly available for the consumer BI and analytics tools.
- Scheduled in Code: Fivetran connects to your Git provider and syncs your dbt models every few minutes to ensure that it is up to date. Once the sync is complete, it runs your dbt models in your destination (as configured) according to the schedule set in your dbt project’s deployment.yml file. The file contains everything you need to get running and simplifies your data stack by eliminating the need for any third-party scheduling tool. All you need to do is edit the deployment file to reflect how often and when you want Fivetran to run your dbt Core models.
Fivetran provides open-source dbt packages that enable analytics-ready aggregated data and canonical schemas in your destination. The source packages expose and document the underlying Fivetran schemas created in the destination. Fivetran Transformations guarantees that alerts produced by dbt Core will immediately appear in the Fivetran Alerts tab. These alerts can be further mapped to email notifications or kept only as a dashboard alert.
From theory to application:
At Tiger Analytics, we created a consumption-ready layer in Snowflake for a US-based financial technology startup. We used Fivetran to extract data from multiple sources leveraging its CDC feature and finally staged into Snowflake. With the implementation of dbt, the staged data was transformed based on business requirements and was finally loaded into the consumption mart in Snowflake.
By doing this we were able to achieve:
- Analytics-ready aggregated data using dbt packages
- Faster implementation that enabled us to provide quicker insights
- Jinja templating with dbt proved very accurate and user-friendly
- Less complex architecture and enhancements that could be added easily in dbt models.
Finally, with this effort, the data from the Snowflake consumption layer was then consumed by the Tableau Dashboard and Data Analytics team and they were able to visualize the data and help the business teams gain valuable insights and make more data-driven decisions.