Modern Data Lake
Data Lake solutions started emerging out of technology innovations such as Big Data but have been propelled by Cloud to a greater extent. The prevalence of Data Lake can be attributed to its ability in bringing better speed to data retrieval compared to Data Warehouses, the elimination of a significant amount of modeling effort, unlocking advanced analytics capabilities for an enterprise, and bringing in storage and compute scalability to handle different kinds of workloads and enable data driven decisions.
Data Democratization is one of the key outcomes that is sought after with the data platforms today. The need to bring reliable and trusted data in a self-service manner to end-users such as data analysts, data scientists, and business users, is the top priority of any data platform. This blog discusses the key trends we see with our clients and in the industry that are being created to aid data lakes cater to wider audiences and to increase their adoption with consumers.

Self-Service Management of Modern Data Lake
“…self-service is basically enabling all types of users (IT or business), to easily manage and govern the data on the lake themselves – in a low/no-code manner”
Building robust, scalable data pipelines is the first step in leveraging data to its full potential. However, it is the incorporation of automation and self-serving capabilities that really helps one achieve that goal. It will also help in democratizing the data, platform, and analytics capabilities to all types of users and reducing the burden on IT teams significantly, so they can focus on high-value tasks.
Building Self-Service Capabilities
Self-serving capabilities are built on top of robust, scalable data pipelines. Any data lake implementation will involve building various reusable frameworks and components for acquiring data from the storage systems (components that can understand and infer the schema, check data quality, implement certain functionalities when bringing in or transforming the data), and loading it into the target zone.
Data pipelines are built using these reusable components and frameworks. These pipelines ingest, wrangle, transform and perform the egress of the data. Stopping at this point would rob an organization of the opportunity to leverage the data to its full potential.
In order to maximize the result, APIs (following microservices architecture) for data and platform management are created to perform CRUD operations and for monitoring purposes. They can also be used to schedule and trigger pipelines, discover and manage datasets, cluster management, security, and user management. Once the APIs are set, you can build a web UI-based interface that can orchestrate all these operations and help any user to navigate it, bring in the data, transform the data, send out the data, or manage the pipelines.
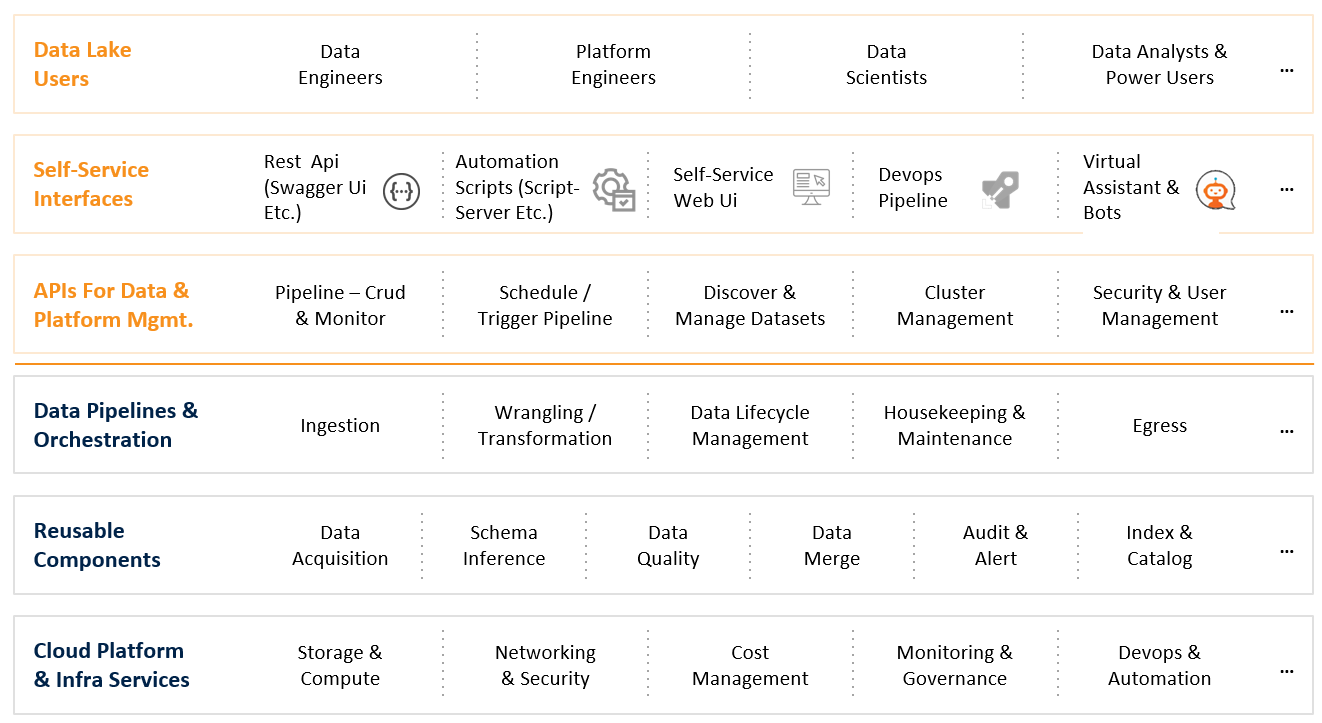
Tiger has also taken self-servicing on Data Lake to another level by building a virtual assistant that interacts with the user to perform the above-mentioned tasks.
Data Catalog Solution
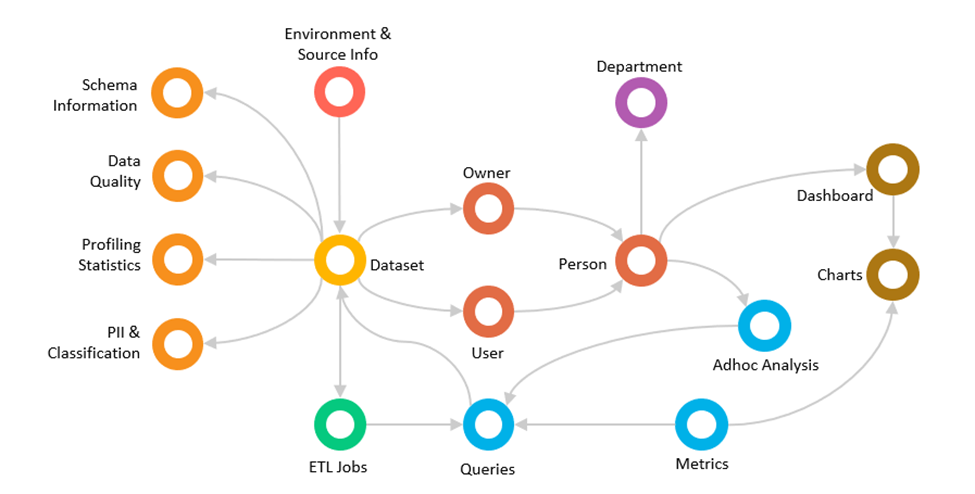
Another common trend we see in modern data lakes is the increasing adoption of next-gen Data Catalog Solutions. A Data Catalog Solution comes in handy when we’re dealing with huge volumes of data and multiple data sets. It can extract and understand technical metadata from different datasets, link them together, understand their health, reliability, and usage patterns, and help any consumer, whether it is a data scientist or a data analyst, or a business analyst, with insight generation.
Data Catalogs have been around for quite some time, but now they are becoming more information intelligent. It is no longer just about bringing in the technical metadata.
Data Catalog Implementation
Some of the vital parts of building a data catalog are using knowledge graphs and powerful search technologies. A knowledge graph solution can bring in the information of a dataset like schema, data quality, profiling statistics, PII, and classification. It can also figure out who’s the owner of the particular dataset, who are the users consuming this data set from various logs, and which department the person belongs to.
This knowledge graph can be used to carry out search and filter operations, graph queries, recommendations, and visual explorations.
Data and Platform Observability
Tiger looks at Observability in three different stages:
1. Basic Data Health Monitoring
2. Advanced Data Health Monitoring with Predictions
3. Extending to Platform Observability
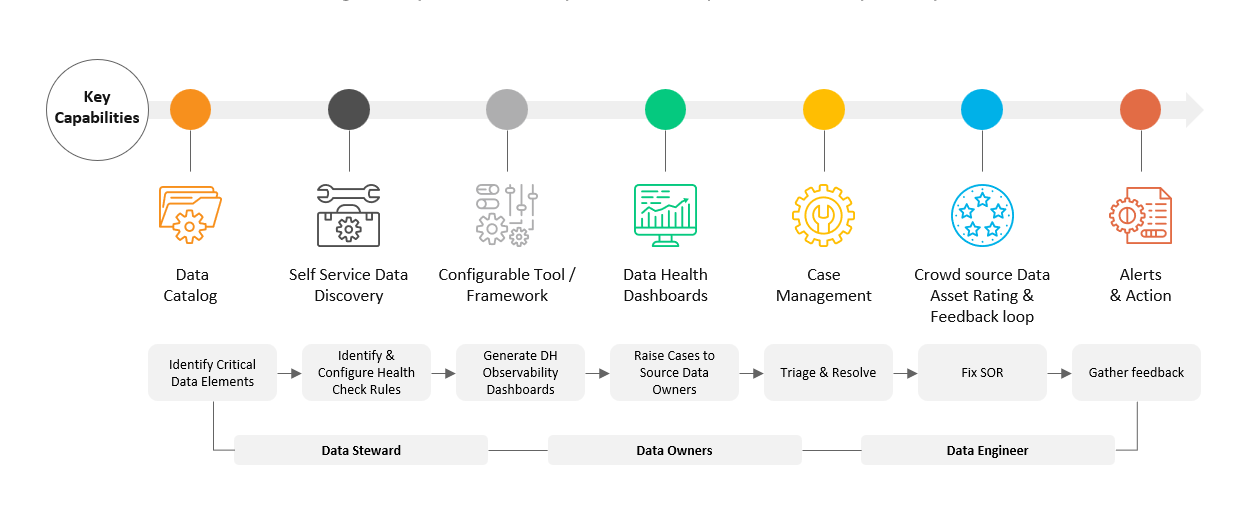
Basic Data Health Monitoring
Identifying critical data elements (CDE) and monitoring them is the most basic aspect of data health monitoring. We configure rule-based data checks against these CDEs and capture the results on a periodic basis and provide visibility through dashboards. These issues are also tracked through ticketing systems and then fixed in source as much as possible. This process constitutes the first stage in ensuring Data Observability.
The key capabilities that are required to achieve this level of maturity are shown below
Advanced Data Health Monitoring with Predictions
Most of the enterprise clients we work with have reached the Basic Data Health Monitoring stage and are looking to progress forward. The observability ecosystem needs to be enhanced with some important capabilities that will help to move from a reactive response to a more proactive one. Artificial Intelligence and Machine Learning are the latest technologies being leveraged to this end. Some of the key capabilities include measuring the data drift and schema drift, classifying the incoming information automatically with AI/ML, detecting the PII information automatically and processing them appropriately, assigning security entitlements automatically based on similar elements in the data platform, etc. These capabilities will elevate the health of the data to the next level also giving early warnings when some data patterns are changing.
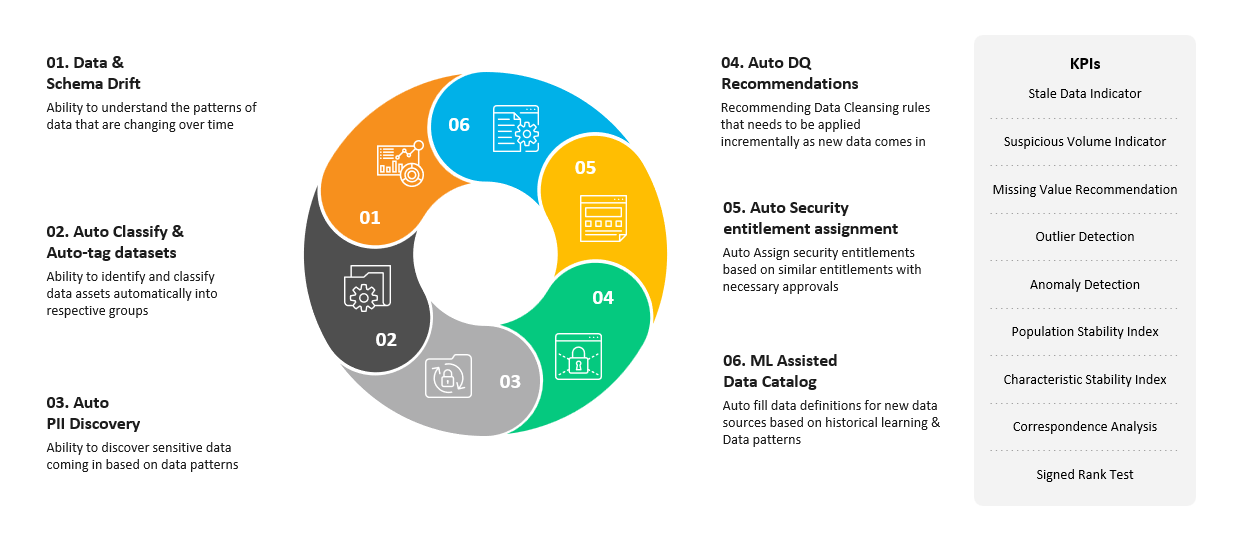
Extending to Platform Observability
The end goal of Observability Solutions is to deliver reliable data to consumers in a timely fashion. This goal can be achieved only when we move beyond data observability into the actual platform that delivers the data itself. This platform has to be modern and state of the art so that it can deliver the data in a timely manner while also allowing engineers and administrators to understand and debug if things are not going well. Following are some of the key capabilities that we need to think about to improve the platform-level observability.
- Monitoring Data Flows & Environment: Ability to monitor job performance degradation, server health, and historical resource utilization trends in real-time
- Monitor Performance: Understanding how data flows from one system to another and looking for bottlenecks in a visual manner would be very helpful in complex data processing environments
- Monitor Data Security: Query logs, access patterns, security tools, etc need to be monitored in order to ensure there is no misuse of data
- Analyze Workloads: Automatically detecting issues and constraints in large data workloads that make them slow and building tools for Root Cause Analysis
- Predict Issues, Delays, and Find Resolutions: Comparing historical performance to current operational efficiency, in terms of speed and resource usage, to predict issues and offer solutions
- Optimize Data Delivery: Building tools into the system that continuously adjust resource allocation based on data-volume spike predictions and thus optimizing TCO
Conclusion
The Modern Data Lake environment is driven by the value of data democratization. It is important to make data management and insight gathering accessible to end-users of all kinds. Self Service aided by Intelligent Data Catalogs is the most promising solution for effective data democratization. Moreover, enabling trust in the data for the data consumers is also of utmost importance. The capabilities discussed such as Data and Platform Observability gives users real under-the-hood control over onboarding, processing, and delivering data to different consumers. Companies are striving to create end-to-end observability solutions and wanting to enable data driven decisions today and these will be the solutions that will take data platforms to the next level of adoption and democratization.