Scenario # 1:
Thousands of files flood the data lake every day. These files are dumped in parallel by the source system, resulting in a massive influx of data.
Scenario #2:
There’s a continuous influx of incremental data from a transactional table in SAP. Every 15 minutes, a massive file containing millions of records has to be extracted and sent to the data lake landing zone. This critical dataset is essential for the business, but the sheer volume of data and the complexity of the transactional system poses significant challenges.
How would you tackle these situations?
In today’s data-driven world, organizations heavily rely on efficient data processing to extract valuable insights. Streamlined data processing directly impacts decision-making – enabling them to unlock hidden patterns, optimize operations, and drive innovation. But often, as businesses keep growing, they are faced with the uphill task of managing data velocity, variety, and volume.
Can data ingestion services help simplify the data loading process, so that business teams can focus on analyzing the data rather than managing the intricate loading process?
Leveraging Databricks to elevate data processing
The process of collecting, transforming, and loading data into a data lake can be complex and time-consuming. At Tiger Analytics, we’ve used Databricks Auto Loader across our clients and various use cases to make the data ingestion process hassle-free.
Here’s how we tackled the two problem statements for our clients:
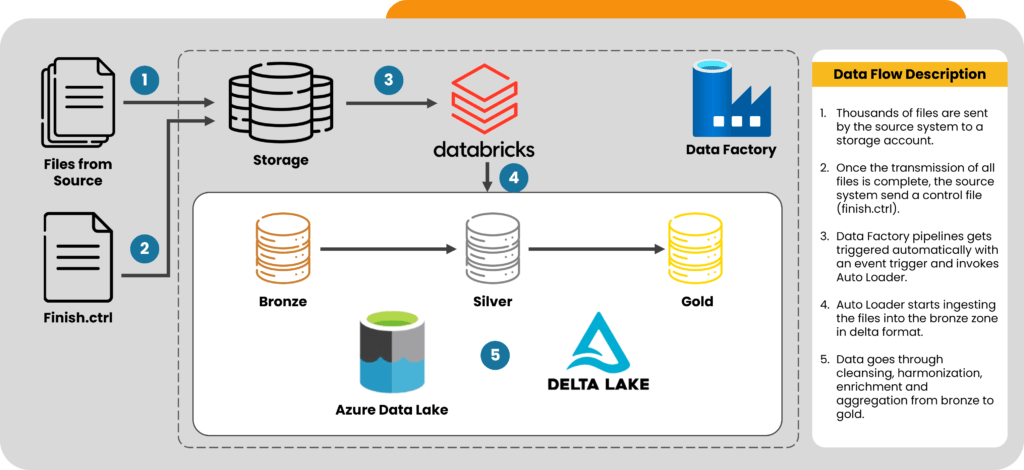
Scenario 1: Multiple File Ingestion Based on Control File Trigger
Thousands of files flooded our client’s data lake daily. The source system would dump them in parallel, resulting in a massive influx of data. Then, to indicate the completion of the extraction process, the source system dropped a control file named ‘finish.ctrl’. The primary challenge was to trigger the ingestion process based on this control file and efficiently load all the files dropped by the source system.
The challenges:
- Large number of files: The daily extract consisted of a staggering 10,000 to 20,000 text files, making manual processing impractical and time-consuming.
- Volume of records: Each file contained hundreds of thousands of records, further complicating the data processing task.
- Timely refresh of silver and gold layers: The business required their Business Intelligence (BI) reports to be refreshed within an hour, necessitating a streamlined and efficient data ingestion process.
- Duplicate file loading: In cases where the extraction process failed at the source, the entire process would start again, resulting in the redundant loading of previously processed files.
How we effectively used Databricks to streamline the ingestion process:
We worked with Databricks Auto Loader by automating the detection and ingestion of thousands of files. With the help of these efforts, the team experienced increased efficiency, improved data quality, and accelerated data processing times – revolutionizing their entire data ingestion process.
The implementation involved the following steps:
- Setting up a data factory orchestrator: The team leveraged Azure Data Factory as an orchestrator to trigger a Databricks notebook based on the event trigger. Specifically, they configured the event trigger to be activated when the source system dropped the control file ‘finish.ctrl’.
- Configuring the Auto Loader notebook: The team coded a Databricks notebook to run Auto Loader with the trigger once option. This configuration ensured that the notebook would run once, ingesting all the files into the bronze table before automatically terminating them.
Sample code snippet:
df = (spark.readStream
.format(“cloudFiles”)
.option(“cloudFiles.format”, <file_format>)
.schema(<schema>))
df.writeStream
.format(‘delta’)
.trigger(once = True)
.outputMode(‘append’)
.option(“checkpointLocation”, <CheckpointLocation>)
.option(“path”,<path>)
.table(<table_name>)
query.awaitTermination()
Business impact:
- Increased efficiency: Manually processing thousands of files became a thing of the past. The client saved significant time and valuable resources by automating the data ingestion process.
- Improved data quality: Ingesting data into the data lake using Databricks Delta Lake ensured enhanced data quality and consistency. This, in turn, mitigated the risk of data errors and inconsistencies.
- Faster data processing: With the automation of data ingestion and improved data quality, the client could achieve lightning-fast file processing times. Files that previously took hours to process were now handled within minutes, empowering the team to make data-driven decisions swiftly.
Scenario 2: Streamlining the Data Ingestion Pipeline
Our client was dealing with managing a continuous influx of incremental data from a transactional table in SAP. Every 15 minutes, a massive file containing millions of records had to be extracted and sent to the data lake landing zone. While the critical dataset was essential for their business, the sheer volume of data and the complexity of the transactional system posed huge challenges.
The challenges:
- Managing a large volume of data: The transactional system generated millions of transactions per hour, resulting in an overwhelming volume of data that needed to be ingested, processed, and analyzed.
- Ordered file processing: It was crucial to process the incremental files in the correct order to maintain data consistency and accuracy with the source system.
- Near real-time data processing: Due to the critical nature of the data, the business required immediate ingestion of the files as soon as they arrived in the landing zone, enabling near real-time data processing.
Using Databricks to enable efficient incremental file processing
The team strategically decided to implement Databricks Auto Loader streaming. This feature allowed them to process new data files incrementally and effectively as they arrived in the cloud storage.
The implementation involved the following steps:
- Leveraging file notification and queue services: The team configured Auto Loader to use the file notification service and queue service, which subscribed to file events from the input directory. This setup ensured that new data files were promptly detected and processed.
- Custom role creation for service principle: To enable the file notification service, the team created a custom role for the service principle. This role encompassed the necessary permissions to create the queue and event subscription required for seamless file notification.
Sample code snippet:
“permissions”: [
{
“actions”: [
“Microsoft.EventGrid/eventSubscriptions/write”,
“Microsoft.EventGrid/eventSubscriptions/read”,
“Microsoft.EventGrid/eventSubscriptions/delete”,
“Microsoft.EventGrid/locations/eventSubscriptions/read”,
“Microsoft.Storage/storageAccounts/read”,
“Microsoft.Storage/storageAccounts/write”,
“Microsoft.Storage/storageAccounts/queueServices/read”,
“Microsoft.Storage/storageAccounts/queueServices/write”,
“Microsoft.Storage/storageAccounts/queueServices/queues/write”,
“Microsoft.Storage/storageAccounts/queueServices/queues/read”,
“Microsoft.Storage/storageAccounts/queueServices/queues/delete”
],
“notActions”: [],
“dataActions”: [
“Microsoft.Storage/storageAccounts/queueServices/queues/messages/delete”,
“Microsoft.Storage/storageAccounts/queueServices/queues/messages/read”,
“Microsoft.Storage/storageAccounts/queueServices/queues/messages/write”,
“Microsoft.Storage/storageAccounts/queueServices/queues/messages/process/action”
],
“notDataActions”: []
}
]
df = ( spark.readStream
.format(“cloudFiles”)
.option(“cloudFiles.format”, <file_format>)
.option(“cloudFiles.useNotifications”,”true”)
.option(“cloudFiles.resourceGroup”,<resource_group_name>)
.option(“cloudFiles.subscriptionId”,<subscription_id>)
.option(“cloudFiles.tenantId”,<tenant_id>)
.option(“cloudFiles.clientId”,<service_principle_client_id>)
.option(“cloudFiles.clientSecret”,<service_principle_secret>)
.option(“cloudFiles.maxFilesPerTrigger”, 1)
.schema(<schema>)
.load(<path>))
input_df.writeStream
.format(“delta”)
.foreachBatch(<function_for_data_processing>)
.outputMode(“update”)
.option(“checkpointLocation”, <checkpoint_location>)
.start()
Business impact:
- Automated data discovery and loading: Auto Loader automated the process of identifying new data files as they arrived in the data lake and automatically loaded the data into the target tables. This eliminated the manual effort required for managing the data loading process.
- Enhanced focus on data analysis: The client could shift from managing the loading process to analyzing the data by streamlining the data ingestion process. Hence, they derived valuable insights and could make informed business decisions promptly.
Making Databricks Auto Loader Work for You
If you’re using Databricks to manage data ingestion, keep these things in mind so that you can create maximum value for your clients:
- Data discovery: Since Databricks Auto Loader automatically detects new data files as they arrive in the data lake, it eliminates the need for manual scanning thus saving time while ensuring no data goes unnoticed.
- Automatic schema inference: The Auto Loader can automatically infer the schema of incoming files based on the file format and structure. It also supports changes in the schema. This means that you can choose to drop new columns, fail on change, or rescue new columns and store them separately. It facilitates smooth data ingestion without delays during schema changes. There’s also no need to define the schema manually, making the loading process more seamless and less error-prone.
- Parallel processing: Databricks Auto Loader is designed to load data into target tables in parallel. This will come in handy when you need to handle large volumes of data efficiently.
- Delta Lake integration: Databricks Auto Loader seamlessly integrates with Delta Lake – open-source data storage and management system optimized for data processing and analytics workloads. You can therefore access leverage Delta Lake’s unique features like ACID transactions, versioning, time travel, and more.
- Efficient job restarts: The Auto Loader stores metadata about the processed data in RocksDB as key-value pairs, enabling seamless job restarts without the need to log failures in the check-point location.
- Spark structured streaming: The Auto Loader leverages Spark structured streaming for immediate data processing, providing real-time insights.
- Flexible file identification: The Auto Loader provides two options for identifying new files – directory listing and file notification. The directory list mode allows the quick launching of an Auto Loader stream without additional permissions. At the same time, file notification and queue services eliminate the need for directory listing in cases of large input directories or unordered file volumes.
- Batch workloads compatibility: While the Auto Loader excels in streaming and processing hundreds of files, it can also be used for batch workloads. This eliminates the need for running continuous clusters. In addition, with check-pointing, you can start and stop streams efficiently. The Auto Loader can also be scheduled for regular batch loads using the trigger once option, leveraging all its features.
Data ingestion and processing are crucial milestones in the Data Management journey. While organizations can generate vast amounts of data, it’s important to ingest and process that data correctly for accurate insights. With services like Databricks, the data-loading process becomes simpler and more efficient, improving output accuracy and empowering organizations to make data-driven decisions.